 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSayer: Using Implicit Feedback to Optimize System Policies
Paper and Code
Oct 28, 2021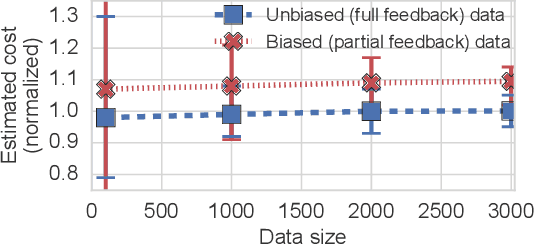

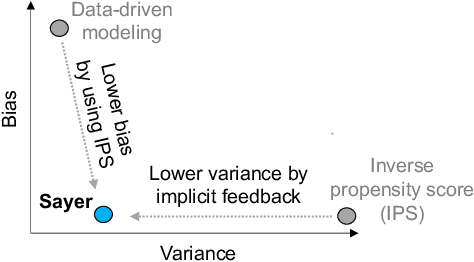

We observe that many system policies that make threshold decisions involving a resource (e.g., time, memory, cores) naturally reveal additional, or implicit feedback. For example, if a system waits X min for an event to occur, then it automatically learns what would have happened if it waited <X min, because time has a cumulative property. This feedback tells us about alternative decisions, and can be used to improve the system policy. However, leveraging implicit feedback is difficult because it tends to be one-sided or incomplete, and may depend on the outcome of the event. As a result, existing practices for using feedback, such as simply incorporating it into a data-driven model, suffer from bias. We develop a methodology, called Sayer, that leverages implicit feedback to evaluate and train new system policies. Sayer builds on two ideas from reinforcement learning -- randomized exploration and unbiased counterfactual estimators -- to leverage data collected by an existing policy to estimate the performance of new candidate policies, without actually deploying those policies. Sayer uses implicit exploration and implicit data augmentation to generate implicit feedback in an unbiased form, which is then used by an implicit counterfactual estimator to evaluate and train new policies. The key idea underlying these techniques is to assign implicit probabilities to decisions that are not actually taken but whose feedback can be inferred; these probabilities are carefully calculated to ensure statistical unbiasedness. We apply Sayer to two production scenarios in Azure, and show that it can evaluate arbitrary policies accurately, and train new policies that outperform the production policies.