 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-REF: Rethinking Image-Prompt Synergy for Refinement in Segment Anything
Paper and Code
Aug 22, 2024
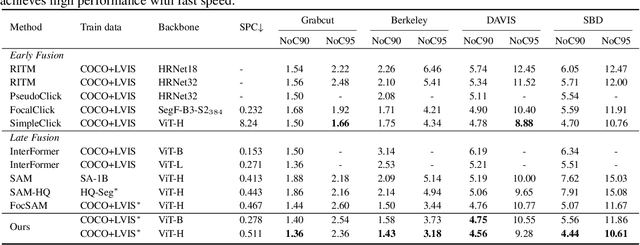
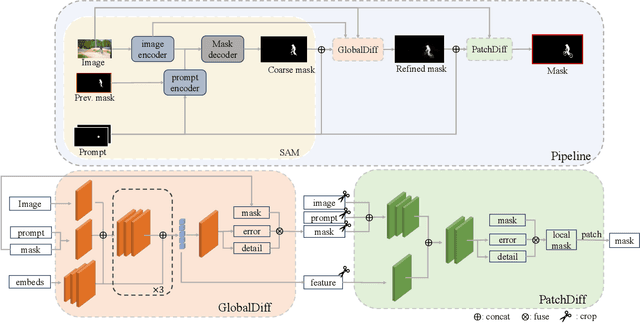
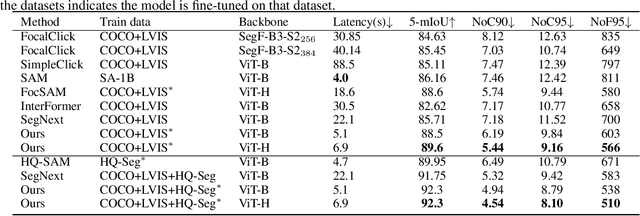
The advent of the Segment Anything Model (SAM) marks a significant milestone for interactive segmentation using generalist models. As a late fusion model, SAM extracts image embeddings once and merges them with prompts in later interactions. This strategy limits the models ability to extract detailed information from the prompted target zone. Current specialist models utilize the early fusion strategy that encodes the combination of images and prompts to target the prompted objects, yet repetitive complex computations on the images result in high latency. The key to these issues is efficiently synergizing the images and prompts. We propose SAM-REF, a two-stage refinement framework that fully integrates images and prompts globally and locally while maintaining the accuracy of early fusion and the efficiency of late fusion. The first-stage GlobalDiff Refiner is a lightweight early fusion network that combines the whole image and prompts, focusing on capturing detailed information for the entire object. The second-stage PatchDiff Refiner locates the object detail window according to the mask and prompts, then refines the local details of the object. Experimentally, we demonstrated the high effectiveness and efficiency of our method in tackling complex cases with multiple interactions. Our SAM-REF model outperforms the current state-of-the-art method in most metrics on segmentation quality without compromising efficiency.