 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-CLIP: Merging Vision Foundation Models towards Semantic and Spatial Understanding
Paper and Code
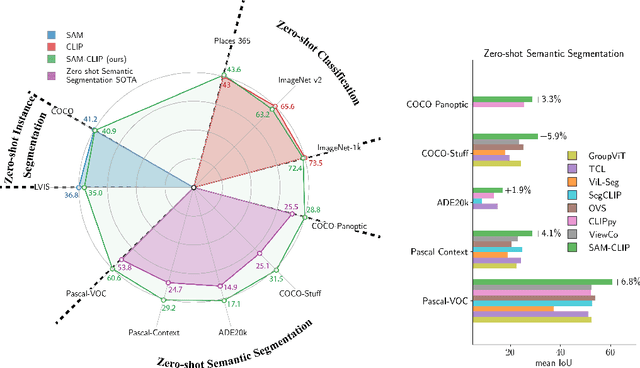
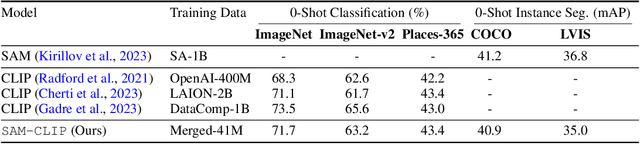
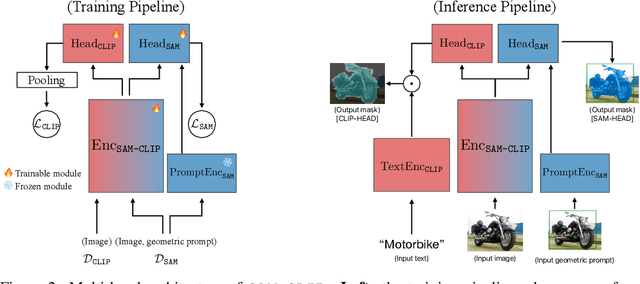

The landscape of publicly available vision foundation models (VFMs), such as CLIP and Segment Anything Model (SAM), is expanding rapidly. VFMs are endowed with distinct capabilities stemming from their pre-training objectives. For instance, CLIP excels in semantic understanding, while SAM specializes in spatial understanding for segmentation. In this work, we introduce a simple recipe to efficiently merge VFMs into a unified model that assimilates their expertise. Our proposed method integrates multi-task learning, continual learning techniques, and teacher-student distillation. This strategy entails significantly less computational cost compared to traditional multi-task training from scratch. Additionally, it only demands a small fraction of the pre-training datasets that were initially used to train individual models. By applying our method to SAM and CLIP, we derive SAM-CLIP: a unified model that amalgamates the strengths of SAM and CLIP into a single backbone, making it apt for edge device applications. We show that SAM-CLIP learns richer visual representations, equipped with both localization and semantic features, suitable for a broad range of vision tasks. SAM-CLIP obtains improved performance on several head probing tasks when compared with SAM and CLIP. We further show that SAM-CLIP not only retains the foundational strengths of its precursor models but also introduces synergistic functionalities, most notably in zero-shot semantic segmentation, where SAM-CLIP establishes new state-of-the-art results on 5 benchmarks. It outperforms previous models that are specifically designed for this task by a large margin, including +6.8% and +5.9% mean IoU improvement on Pascal-VOC and COCO-Stuff datasets, respectively.