 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Model-Based Reinforcement Learning Using Robust Control Barrier Functions
Paper and Code
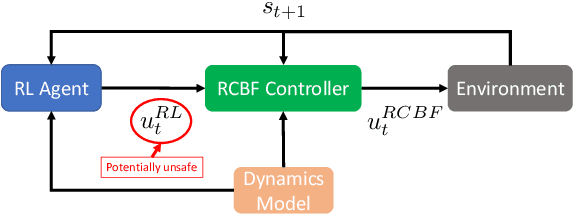
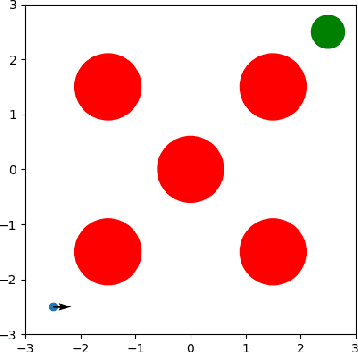
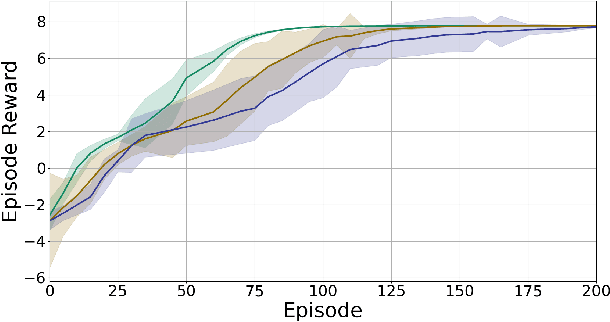
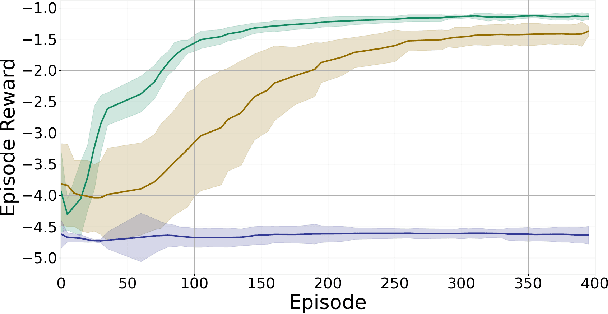
Reinforcement Learning (RL) is effective in many scenarios. However, it typically requires the exploration of a sufficiently large number of state-action pairs, some of which may be unsafe. Consequently, its application to safety-critical systems remains a challenge. Towards this end, an increasingly common approach to address safety involves the addition of a safety layer that projects the RL actions onto a safe set of actions. In turn, a challenge for such frameworks is how to effectively couple RL with the safety layer to improve the learning performance. In the context of leveraging control barrier functions for safe RL training, prior work focuses on a restricted class of barrier functions and utilizes an auxiliary neural net to account for the effects of the safety layer which inherently results in an approximation. In this paper, we frame safety as a differentiable robust-control-barrier-function layer in a model-based RL framework. As such, this approach both ensures safety and effectively guides exploration during training resulting in increased sample efficiency as demonstrated in the experiments.