 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRxWhyQA: a clinical question-answering dataset with the challenge of multi-answer questions
Paper and Code
Jan 07, 2022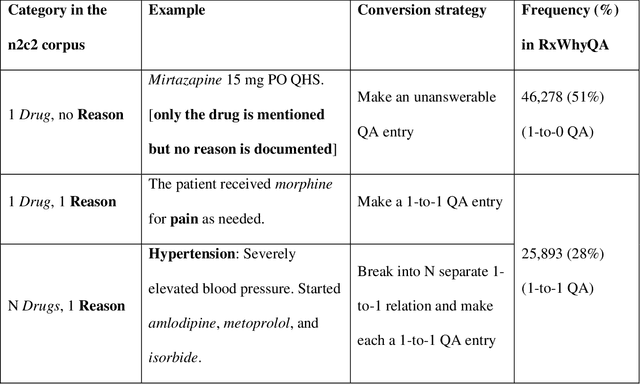
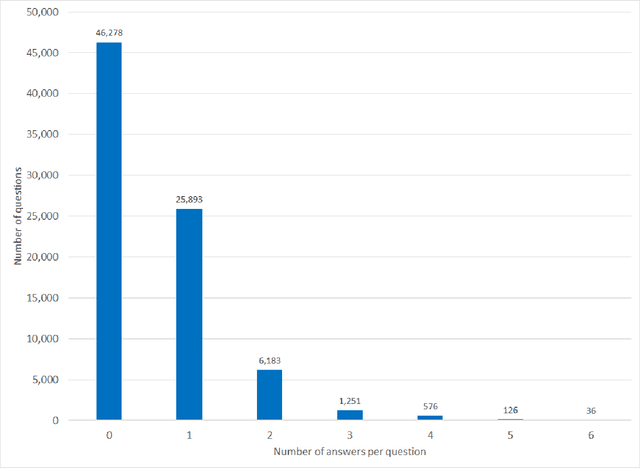


Objectives Create a dataset for the development and evaluation of clinical question-answering (QA) systems that can handle multi-answer questions. Materials and Methods We leveraged the annotated relations from the 2018 National NLP Clinical Challenges (n2c2) corpus to generate a QA dataset. The 1-to-0 and 1-to-N drug-reason relations formed the unanswerable and multi-answer entries, which represent challenging scenarios lacking in the existing clinical QA datasets. Results The result RxWhyQA dataset contains 91,440 QA entries, of which half are unanswerable, and 21% (n=19,269) of the answerable ones require multiple answers. The dataset conforms to the community-vetted Stanford Question Answering Dataset (SQuAD) format. Discussion The RxWhyQA is useful for comparing different systems that need to handle the zero- and multi-answer challenges, demanding dual mitigation of both false positive and false negative answers. Conclusion We created and shared a clinical QA dataset with a focus on multi-answer questions to represent real-world scenarios.