 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering
Paper and Code
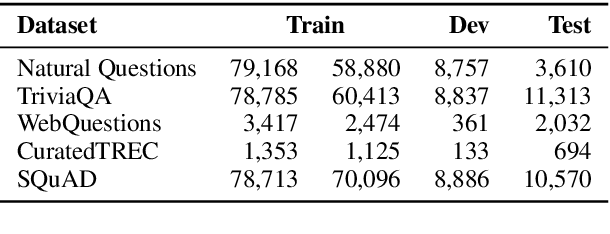
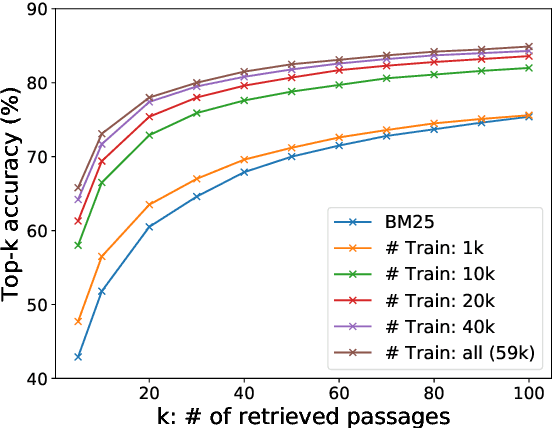
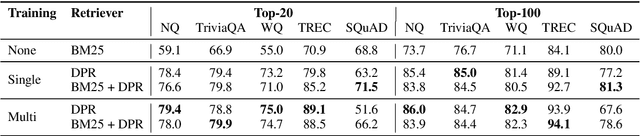
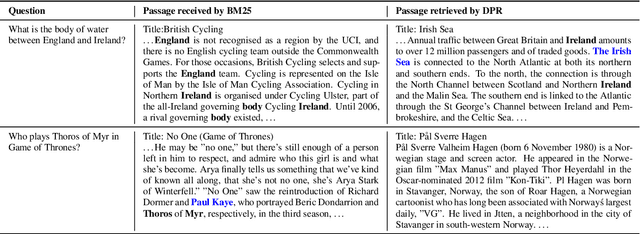
In open-domain question answering, dense passage retrieval has become a new paradigm to retrieve relevant passages for answer finding. Typically, the dual-encoder architecture is adopted to learn dense representations of questions and passages for matching. However, it is difficult to train an effective dual-encoder due to the challenges including the discrepancy between training and inference, the existence of unlabeled positives and limited training data. To address these challenges, we propose an optimized training approach, called RocketQA, to improving dense passage retrieval. We make three major technical contributions in RocketQA, namely cross-batch negatives, denoised negative sampling and data augmentation. Extensive experiments show that RocketQA significantly outperforms previous state-of-the-art models on both MSMARCO and Natural Questions. Besides, built upon RocketQA, we achieve the first rank at the leaderboard of MSMARCO Passage Ranking Task.