 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness Verification for Attention Networks using Mixed Integer Programming
Paper and Code
Feb 08, 2022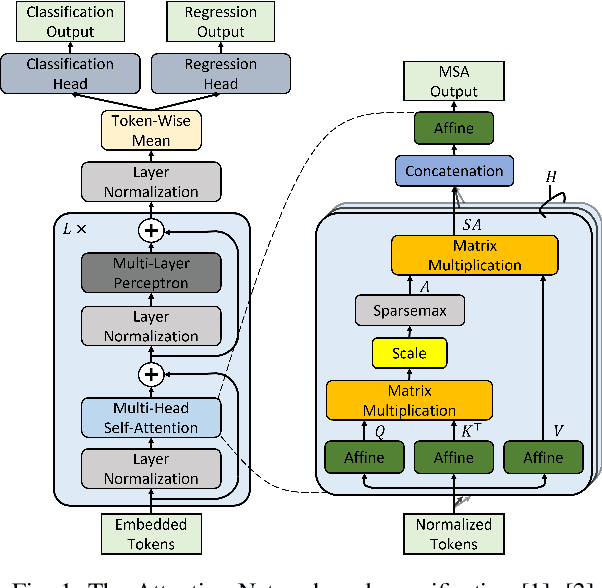

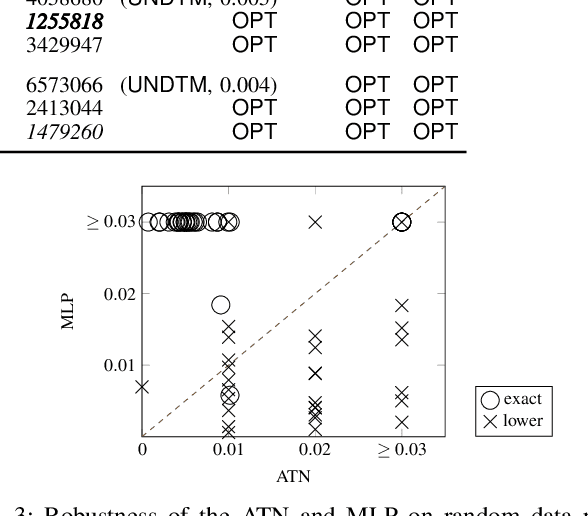
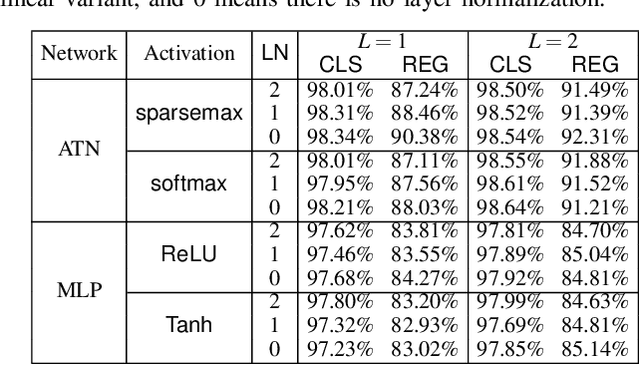
Attention networks such as transformers have been shown powerful in many applications ranging from natural language processing to object recognition. This paper further considers their robustness properties from both theoretical and empirical perspectives. Theoretically, we formulate a variant of attention networks containing linearized layer normalization and sparsemax activation, and reduce its robustness verification to a Mixed Integer Programming problem. Apart from a na\"ive encoding, we derive tight intervals from admissible perturbation regions and examine several heuristics to speed up the verification process. More specifically, we find a novel bounding technique for sparsemax activation, which is also applicable to softmax activation in general neural networks. Empirically, we evaluate our proposed techniques with a case study on lane departure warning and demonstrate a performance gain of approximately an order of magnitude. Furthermore, although attention networks typically deliver higher accuracy than general neural networks, contrasting its robustness against a similar-sized multi-layer perceptron surprisingly shows that they are not necessarily more robust.