 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRNN Training along Locally Optimal Trajectories via Frank-Wolfe Algorithm
Paper and Code
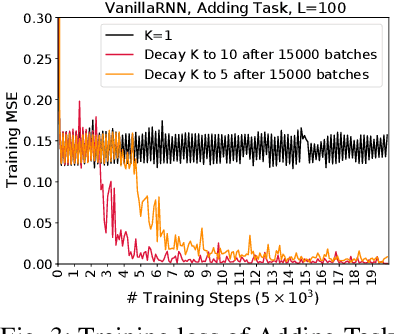
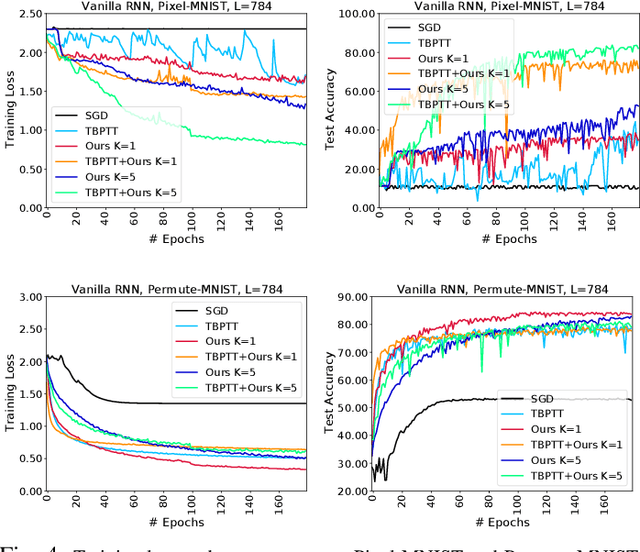
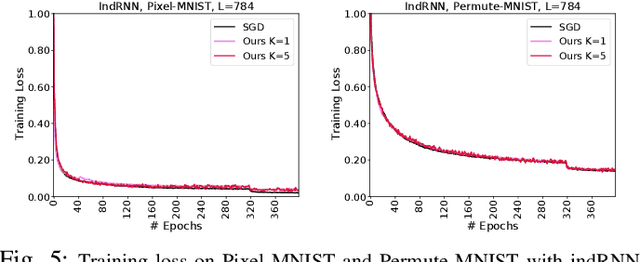
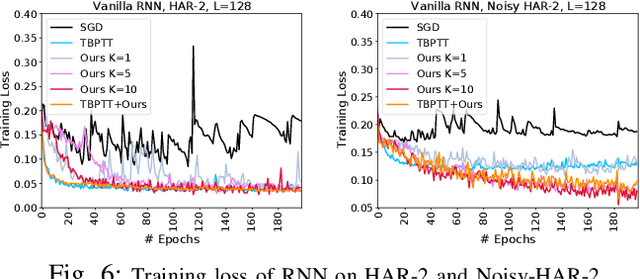
We propose a novel and efficient training method for RNNs by iteratively seeking a local minima on the loss surface within a small region, and leverage this directional vector for the update, in an outer-loop. We propose to utilize the Frank-Wolfe (FW) algorithm in this context. Although, FW implicitly involves normalized gradients, which can lead to a slow convergence rate, we develop a novel RNN training method that, surprisingly, even with the additional cost, the overall training cost is empirically observed to be lower than back-propagation. Our method leads to a new Frank-Wolfe method, that is in essence an SGD algorithm with a restart scheme. We prove that under certain conditions our algorithm has a sublinear convergence rate of $O(1/\epsilon)$ for $\epsilon$ error. We then conduct empirical experiments on several benchmark datasets including those that exhibit long-term dependencies, and show significant performance improvement. We also experiment with deep RNN architectures and show efficient training performance. Finally, we demonstrate that our training method is robust to noisy data.