 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward-Directed Conditional Diffusion: Provable Distribution Estimation and Reward Improvement
Paper and Code
Jul 13, 2023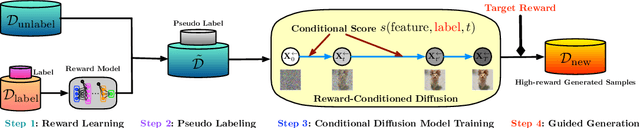
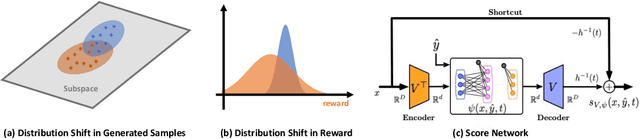
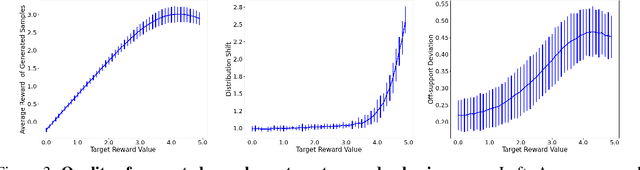
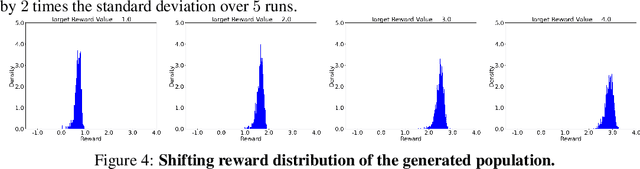
We explore the methodology and theory of reward-directed generation via conditional diffusion models. Directed generation aims to generate samples with desired properties as measured by a reward function, which has broad applications in generative AI, reinforcement learning, and computational biology. We consider the common learning scenario where the data set consists of unlabeled data along with a smaller set of data with noisy reward labels. Our approach leverages a learned reward function on the smaller data set as a pseudolabeler. From a theoretical standpoint, we show that this directed generator can effectively learn and sample from the reward-conditioned data distribution. Additionally, our model is capable of recovering the latent subspace representation of data. Moreover, we establish that the model generates a new population that moves closer to a user-specified target reward value, where the optimality gap aligns with the off-policy bandit regret in the feature subspace. The improvement in rewards obtained is influenced by the interplay between the strength of the reward signal, the distribution shift, and the cost of off-support extrapolation. We provide empirical results to validate our theory and highlight the relationship between the strength of extrapolation and the quality of generated samples.