 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevision in Continuous Space: Fine-Grained Control of Text Style Transfer
Paper and Code


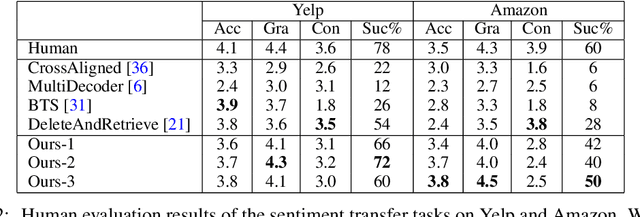
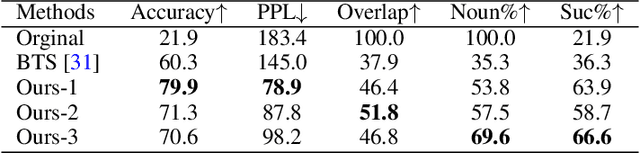
Typical methods for unsupervised text style transfer often rely on two key ingredients: 1) seeking for the disentanglement of the content and the attributes, and 2) troublesome adversarial learning. In this paper, we show that neither of these components is indispensable. We propose a new framework without them and instead consists of three key components: a variational auto-encoder (VAE), some attribute predictors (one for each attribute), and a content predictor. The VAE and the two types of predictors enable us to perform gradient-based optimization in the continuous space, which is mapped from sentences in a discrete space, to find the representation of a target sentence with the desired attributes and preserved content. Moreover, the proposed method can, for the first time, simultaneously manipulate multiple fine-grained attributes, such as sentence length and the presence of specific words, in synergy when performing text style transfer tasks. Extensive experimental studies on three popular text style transfer tasks show that the proposed method significantly outperforms five state-of-the-art methods.