 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Token-Mixing MLP for MLP-based Vision Backbone
Paper and Code
Jun 28, 2021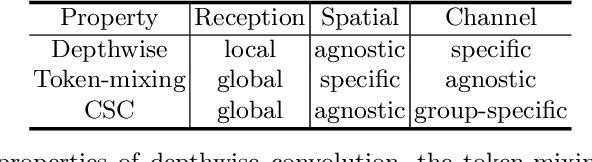
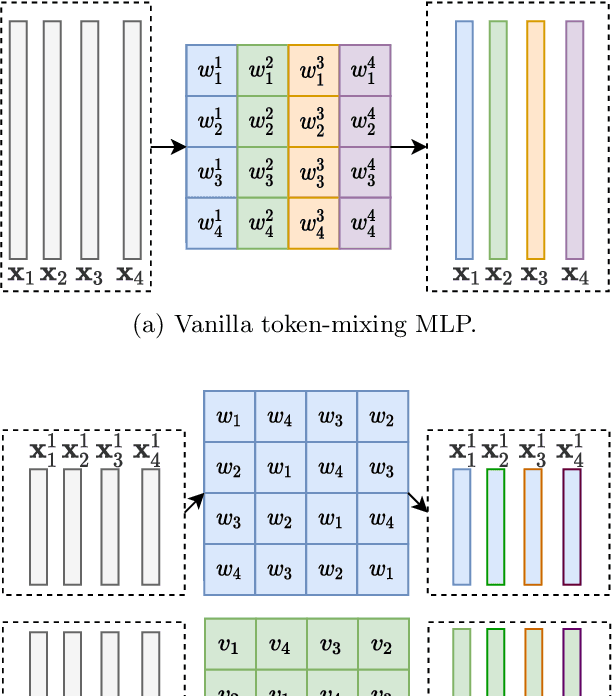


In the past decade, we have witnessed rapid progress in the machine vision backbone. By introducing the inductive bias from the image processing, convolution neural network (CNN) has achieved excellent performance in numerous computer vision tasks and has been established as \emph{de facto} backbone. In recent years, inspired by the great success achieved by Transformer in NLP tasks, vision Transformer models emerge. Using much less inductive bias, they have achieved promising performance in computer vision tasks compared with their CNN counterparts. More recently, researchers investigate using the pure-MLP architecture to build the vision backbone to further reduce the inductive bias, achieving good performance. The pure-MLP backbone is built upon channel-mixing MLPs to fuse the channels and token-mixing MLPs for communications between patches. In this paper, we re-think the design of the token-mixing MLP. We discover that token-mixing MLPs in existing MLP-based backbones are spatial-specific, and thus it is sensitive to spatial translation. Meanwhile, the channel-agnostic property of the existing token-mixing MLPs limits their capability in mixing tokens. To overcome those limitations, we propose an improved structure termed as Circulant Channel-Specific (CCS) token-mixing MLP, which is spatial-invariant and channel-specific. It takes fewer parameters but achieves higher classification accuracy on ImageNet1K benchmark.