 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Truly Unsupervised Image-to-Image Translation
Paper and Code
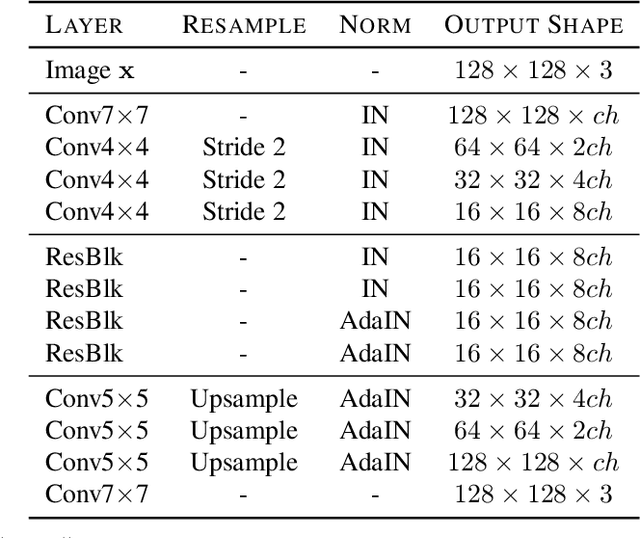

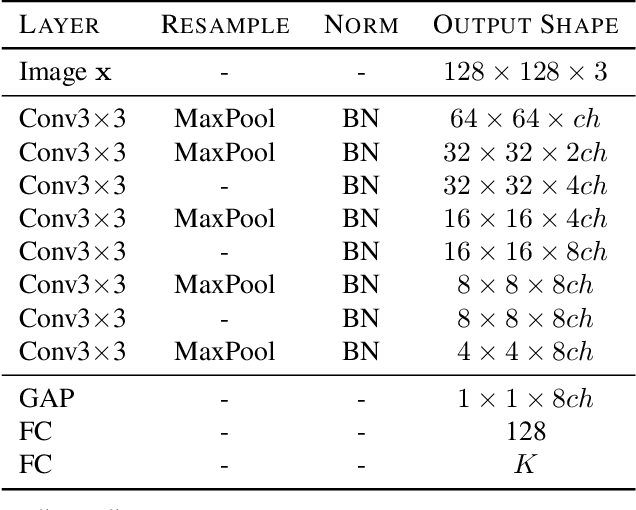
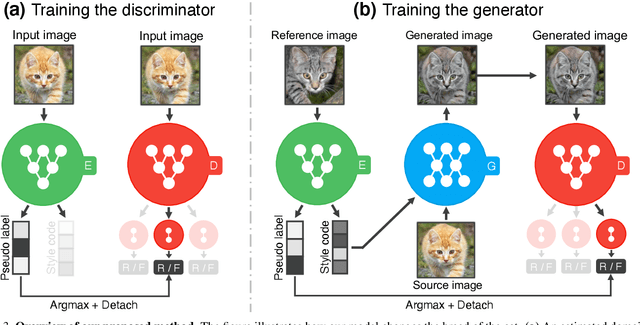
Every recent image-to-image translation model uses either image-level (i.e. input-output pairs) or set-level (i.e. domain labels) supervision at minimum. However, even the set-level supervision can be a serious bottleneck for data collection in practice. In this paper, we tackle image-to-image translation in a fully unsupervised setting, i.e., neither paired images nor domain labels. To this end, we propose the truly unsupervised image-to-image translation method (TUNIT) that simultaneously learns to separate image domains via an information-theoretic approach and generate corresponding images using the estimated domain labels. Experimental results on various datasets show that the proposed method successfully separates domains and translates images across those domains. In addition, our model outperforms existing set-level supervised methods under a semi-supervised setting, where a subset of domain labels is provided. The source code is available at https://github.com/clovaai/tunit