 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Resource Management in Edge Learning: A Joint Pre-training and Fine-tuning Design Paradigm
Paper and Code
Apr 01, 2024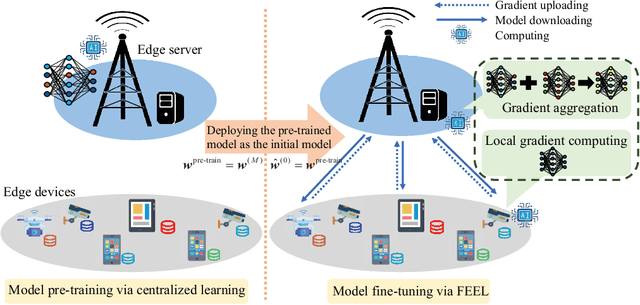
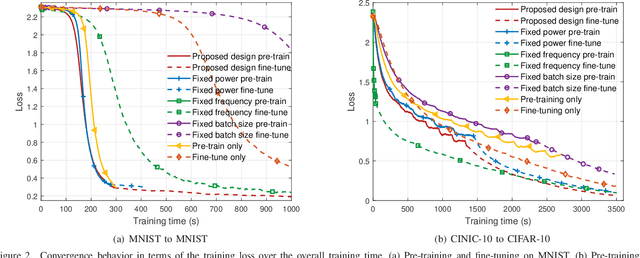
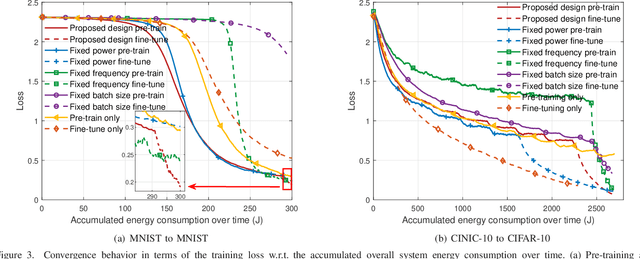
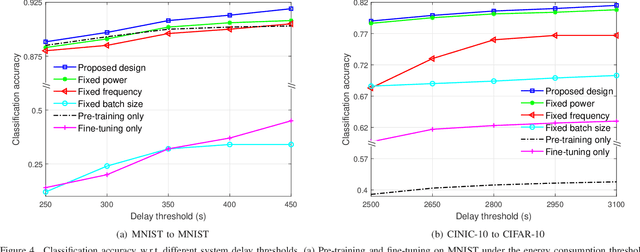
In some applications, edge learning is experiencing a shift in focusing from conventional learning from scratch to new two-stage learning unifying pre-training and task-specific fine-tuning. This paper considers the problem of joint communication and computation resource management in a two-stage edge learning system. In this system, model pre-training is first conducted at an edge server via centralized learning on local pre-stored general data, and then task-specific fine-tuning is performed at edge devices based on the pre-trained model via federated edge learning. For the two-stage learning model, we first analyze the convergence behavior (in terms of the average squared gradient norm bound), which characterizes the impacts of various system parameters such as the number of learning rounds and batch sizes in the two stages on the convergence rate. Based on our analytical results, we then propose a joint communication and computation resource management design to minimize an average squared gradient norm bound, subject to constraints on the transmit power, overall system energy consumption, and training delay. The decision variables include the number of learning rounds, batch sizes, clock frequencies, and transmit power control for both pre-training and fine-tuning stages. Finally, numerical results are provided to evaluate the effectiveness of our proposed design. It is shown that the proposed joint resource management over the pre-training and fine-tuning stages well balances the system performance trade-off among the training accuracy, delay, and energy consumption. The proposed design is also shown to effectively leverage the inherent trade-off between pre-training and fine-tuning, which arises from the differences in data distribution between pre-stored general data versus real-time task-specific data, thus efficiently optimizing overall system performance.