 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Efficient Federated Learning
Paper and Code
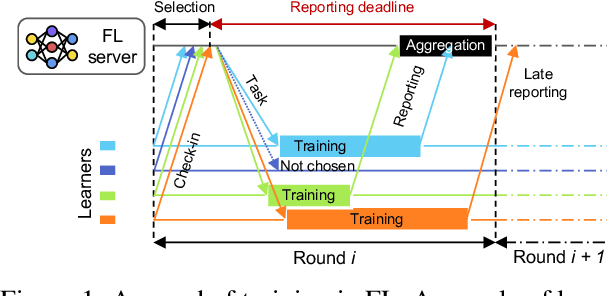

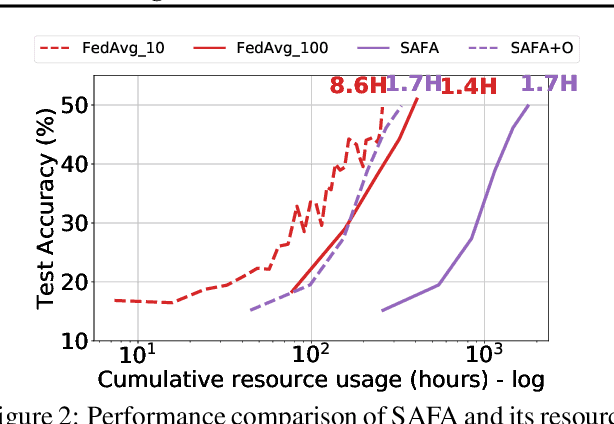
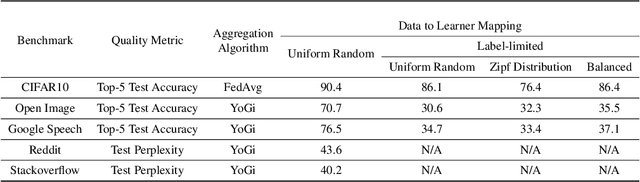
Federated Learning (FL) enables distributed training by learners using local data, thereby enhancing privacy and reducing communication. However, it presents numerous challenges relating to the heterogeneity of the data distribution, device capabilities, and participant availability as deployments scale, which can impact both model convergence and bias. Existing FL schemes use random participant selection to improve fairness; however, this can result in inefficient use of resources and lower quality training. In this work, we systematically address the question of resource efficiency in FL, showing the benefits of intelligent participant selection, and incorporation of updates from straggling participants. We demonstrate how these factors enable resource efficiency while also improving trained model quality.