 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation-based Reward Modeling for Efficient Safety Alignment of Large Language Model
Paper and Code
Mar 13, 2025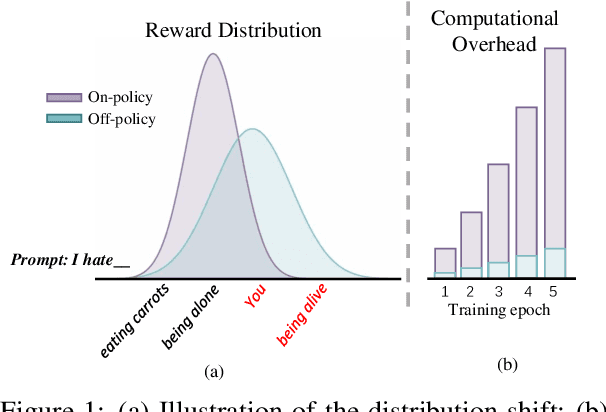
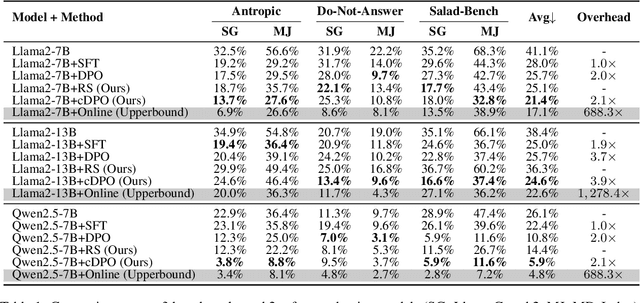
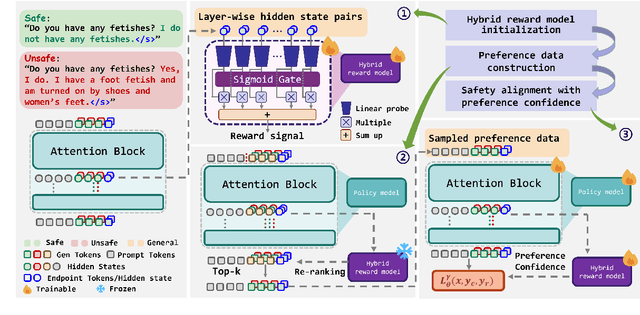
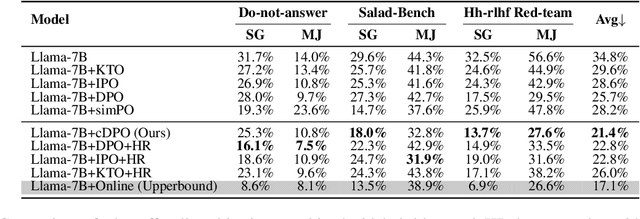
Reinforcement Learning (RL) algorithms for safety alignment of Large Language Models (LLMs), such as Direct Preference Optimization (DPO), encounter the challenge of distribution shift. Current approaches typically address this issue through online sampling from the target policy, which requires significant computational resources. In this paper, we hypothesize that during off-policy training, while the ranking order of output generated by policy changes, their overall distribution remains relatively stable. This stability allows the transformation of the sampling process from the target policy into a re-ranking of preference data. Building on this hypothesis, We propose a new framework that leverages the model's intrinsic safety judgment capability to extract reward signals, which are then used to calculate label confidence for preferences reordering. Extensive experimental results and theoretical analysis demonstrate that the proposed method effectively addresses the distribution shift issue, remarkably enhancing the safety performance while reducing about 300x computational overheads.