 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREO-Relevance, Extraness, Omission: A Fine-grained Evaluation for Image Captioning
Paper and Code

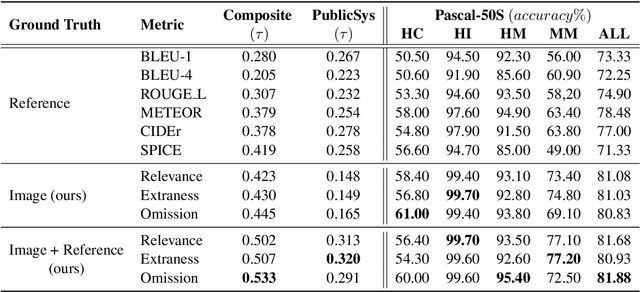
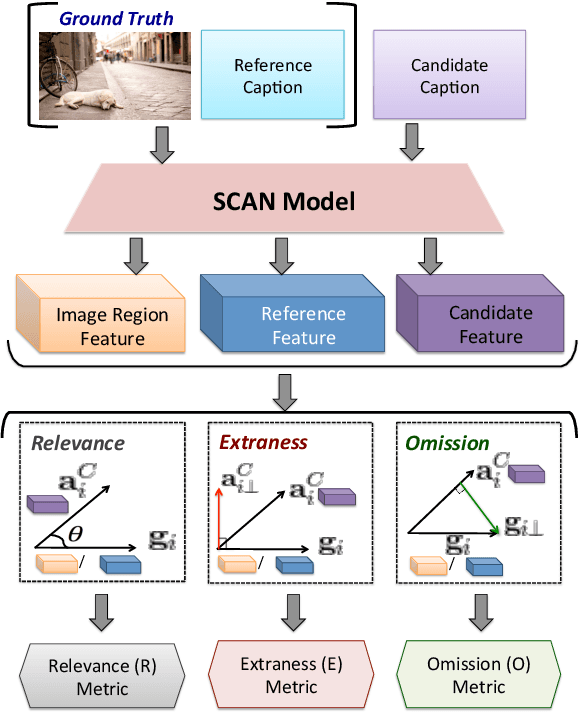

Popular metrics used for evaluating image captioning systems, such as BLEU and CIDEr, provide a single score to gauge the system's overall effectiveness. This score is often not informative enough to indicate what specific errors are made by a given system. In this study, we present a fine-grained evaluation method REO for automatically measuring the performance of image captioning systems. REO assesses the quality of captions from three perspectives: 1) Relevance to the ground truth, 2) Extraness of the content that is irrelevant to the ground truth, and 3) Omission of the elements in the images and human references. Experiments on three benchmark datasets demonstrate that our method achieves a higher consistency with human judgments and provides more intuitive evaluation results than alternative metrics.