 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRELLIS-3D Dataset: Data, Benchmarks and Analysis
Paper and Code
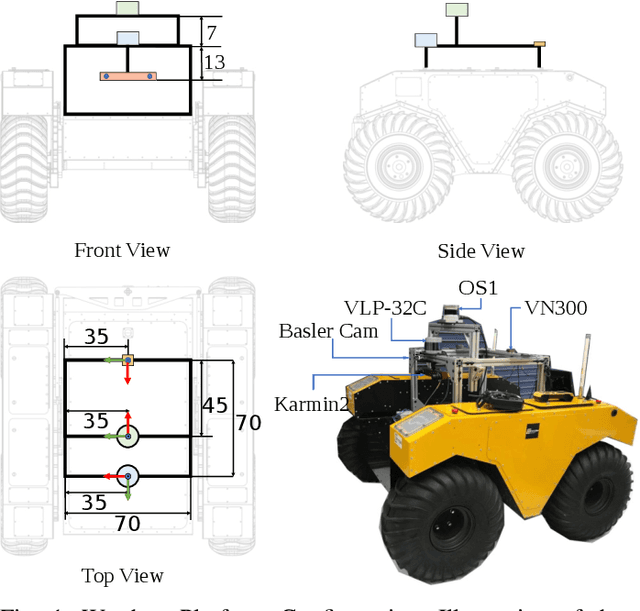

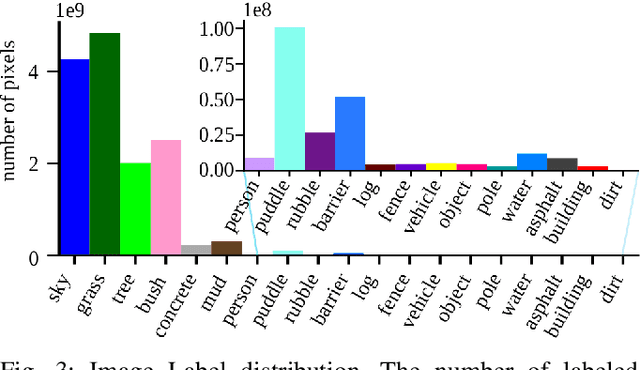
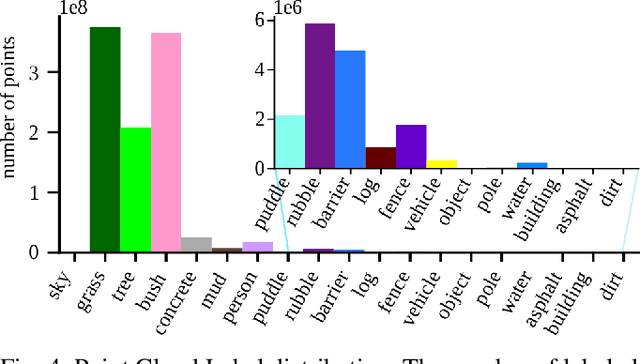
Semantic scene understanding is crucial for robust and safe autonomous navigation, particularly so in off-road environments. Recent deep learning advances for 3D semantic segmentation rely heavily on large sets of training data, however existing autonomy datasets either represent urban environments or lack multimodal off-road data. We fill this gap with RELLIS-3D, a multimodal dataset collected in an off-road environment, which contains annotations for 13,556 LiDAR scans and 6,235 images. The data was collected on the Rellis Campus of Texas A&M University, and presents challenges to existing algorithms related to class imbalance and environmental topography. Additionally, we evaluate the current state of the art deep learning semantic segmentation models on this dataset. Experimental results show that RELLIS-3D presents challenges for algorithms designed for segmentation in urban environments. This novel dataset provides the resources needed by researchers to continue to develop more advanced algorithms and investigate new research directions to enhance autonomous navigation in off-road environments. RELLIS-3D will be published at https://github.com/unmannedlab/RELLIS-3D.