 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing the Variance of Gaussian Process Hyperparameter Optimization with Preconditioning
Paper and Code
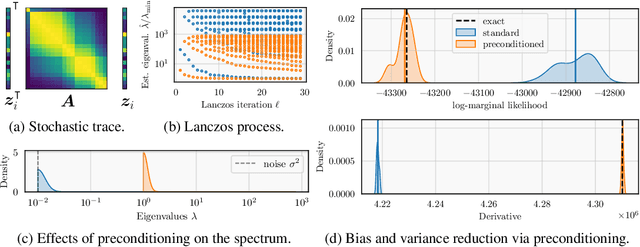



Gaussian processes remain popular as a flexible and expressive model class, but the computational cost of kernel hyperparameter optimization stands as a major limiting factor to their scaling and broader adoption. Recent work has made great strides combining stochastic estimation with iterative numerical techniques, essentially boiling down GP inference to the cost of (many) matrix-vector multiplies. Preconditioning -- a highly effective step for any iterative method involving matrix-vector multiplication -- can be used to accelerate convergence and thus reduce bias in hyperparameter optimization. Here, we prove that preconditioning has an additional benefit that has been previously unexplored. It not only reduces the bias of the $\log$-marginal likelihood estimator and its derivatives, but it also simultaneously can reduce variance at essentially negligible cost. We leverage this result to derive sample-efficient algorithms for GP hyperparameter optimization requiring as few as $\mathcal{O}(\log(\varepsilon^{-1}))$ instead of $\mathcal{O}(\varepsilon^{-2})$ samples to achieve error $\varepsilon$. Our theoretical results enable provably efficient and scalable optimization of kernel hyperparameters, which we validate empirically on a set of large-scale benchmark problems. There, variance reduction via preconditioning results in an order of magnitude speedup in hyperparameter optimization of exact GPs.