 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Distance-Encoding Neural Networks for Graph Representation Learning
Paper and Code
Dec 03, 2023
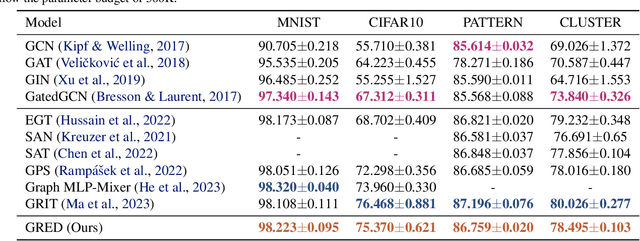


Graph neural networks based on iterative one-hop message passing have been shown to struggle in harnessing information from distant nodes effectively. Conversely, graph transformers allow each node to attend to all other nodes directly, but suffer from high computational complexity and have to rely on ad-hoc positional encoding to bake in the graph inductive bias. In this paper, we propose a new architecture to reconcile these challenges. Our approach stems from the recent breakthroughs in long-range modeling provided by deep state-space models on sequential data: for a given target node, our model aggregates other nodes by their shortest distances to the target and uses a parallelizable linear recurrent network over the chain of distances to provide a natural encoding of its neighborhood structure. With no need for positional encoding, we empirically show that the performance of our model is highly competitive compared with that of state-of-the-art graph transformers on various benchmarks, at a drastically reduced computational complexity. In addition, we show that our model is theoretically more expressive than one-hop message passing neural networks.