 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecovering Petaflops in Contrastive Semi-Supervised Learning of Visual Representations
Paper and Code
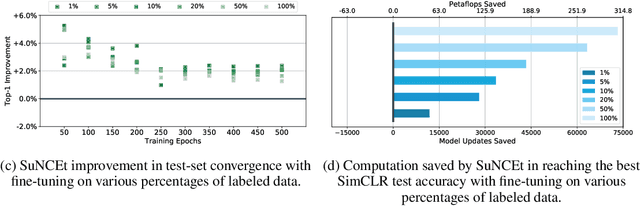
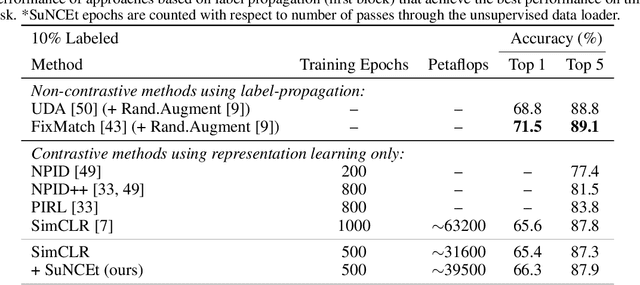
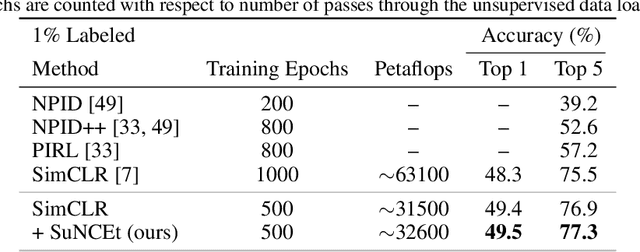

We investigate a strategy for improving the computational efficiency of contrastive learning of visual representations by leveraging a small amount of supervised information during pre-training. We propose a semi-supervised loss, SuNCEt, based on noise-contrastive estimation, that aims to distinguish examples of different classes in addition to the self-supervised instance-wise pretext tasks. We find that SuNCEt can be used to match the semi-supervised learning accuracy of previous contrastive approaches with significantly less computational effort. Our main insight is that leveraging even a small amount of labeled data during pre-training, and not only during fine-tuning, provides an important signal that can significantly accelerate contrastive learning of visual representations.