 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom projections and Kernelised Leave One Cluster Out Cross-Validation: Universal baselines and evaluation tools for supervised machine learning for materials properties
Paper and Code
Jun 17, 2022
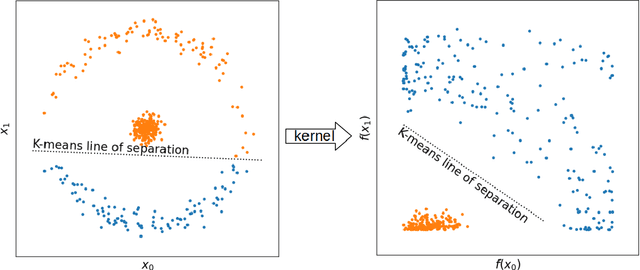
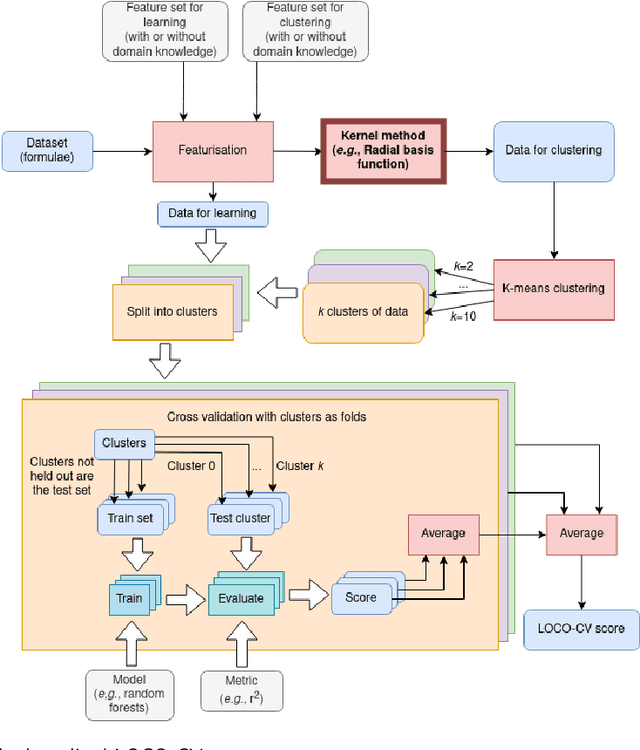
With machine learning being a popular topic in current computational materials science literature, creating representations for compounds has become common place. These representations are rarely compared, as evaluating their performance - and the performance of the algorithms that they are used with - is non-trivial. With many materials datasets containing bias and skew caused by the research process, leave one cluster out cross validation (LOCO-CV) has been introduced as a way of measuring the performance of an algorithm in predicting previously unseen groups of materials. This raises the question of the impact, and control, of the range of cluster sizes on the LOCO-CV measurement outcomes. We present a thorough comparison between composition-based representations, and investigate how kernel approximation functions can be used to better separate data to enhance LOCO-CV applications. We find that domain knowledge does not improve machine learning performance in most tasks tested, with band gap prediction being the notable exception. We also find that the radial basis function improves the linear separability of chemical datasets in all 10 datasets tested and provide a framework for the application of this function in the LOCO-CV process to improve the outcome of LOCO-CV measurements regardless of machine learning algorithm, choice of metric, and choice of compound representation. We recommend kernelised LOCO-CV as a training paradigm for those looking to measure the extrapolatory power of an algorithm on materials data.