 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadiology Report Generation with a Learned Knowledge Base and Multi-modal Alignment
Paper and Code
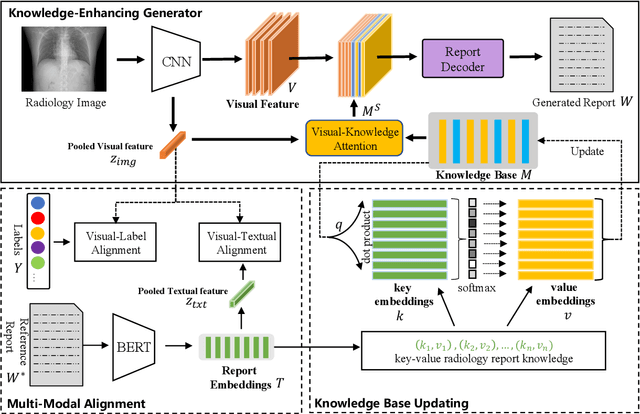
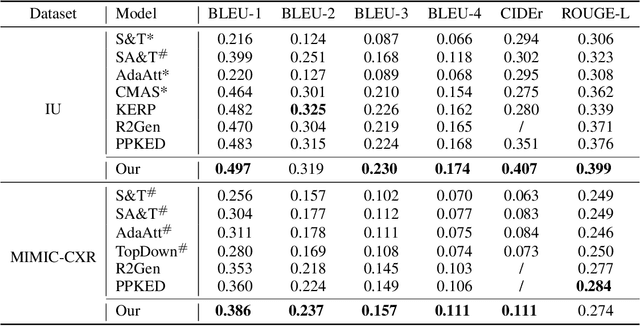
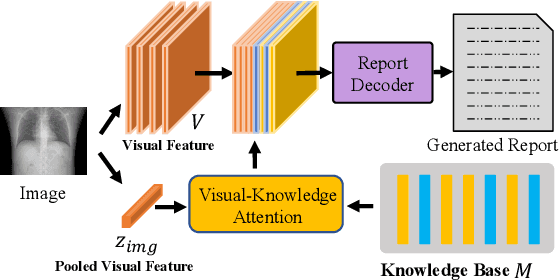
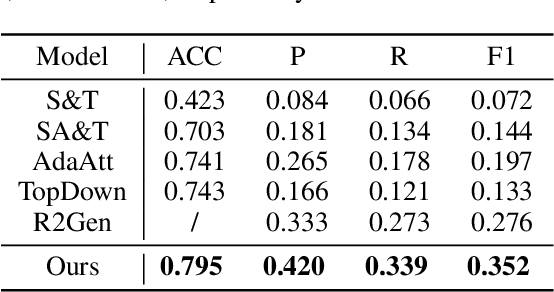
In clinics, a radiology report is crucial for guiding a patient's treatment. Unfortunately, report writing imposes a heavy burden on radiologists. To effectively reduce such a burden, we hereby present an automatic, multi-modal approach for report generation from chest x-ray. Our approach, motivated by the observation that the descriptions in radiology reports are highly correlated with the x-ray images, features two distinct modules: (i) Learned knowledge base. To absorb the knowledge embedded in the above-mentioned correlation, we automatically build a knowledge base based on textual embedding. (ii) Multi-modal alignment. To promote the semantic alignment among reports, disease labels and images, we explicitly utilize textual embedding to guide the learning of the visual feature space. We evaluate the performance of the proposed model using metrics from both natural language generation and clinic efficacy on the public IU and MIMIC-CXR datasets. Our ablation study shows that each module contributes to improving the quality of generated reports. Furthermore, with the aid of both modules, our approach clearly outperforms state-of-the-art methods.