 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAM: Texture Recognition through Randomized Aggregated Encoding of Deep Activation Maps
Paper and Code
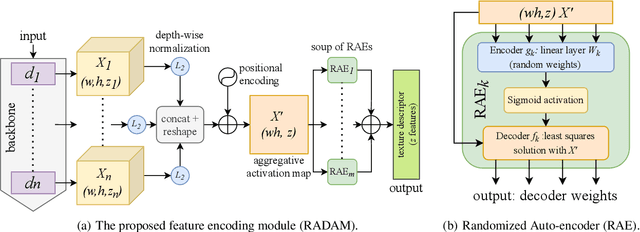
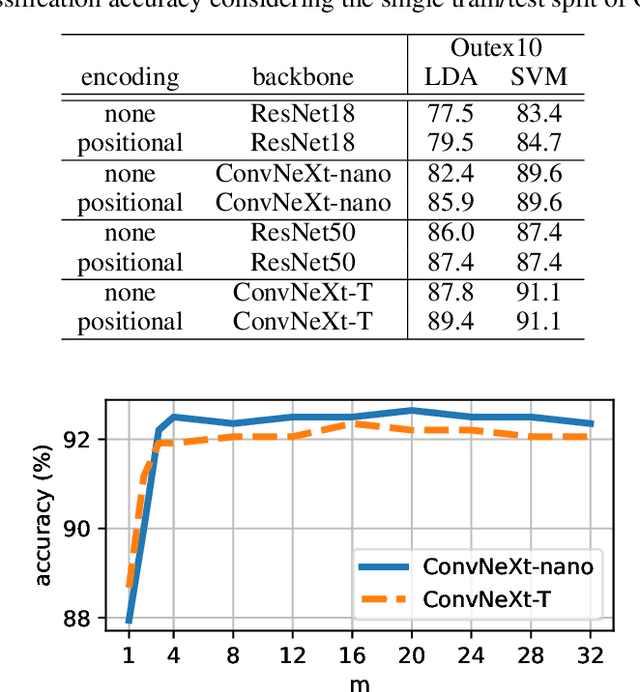
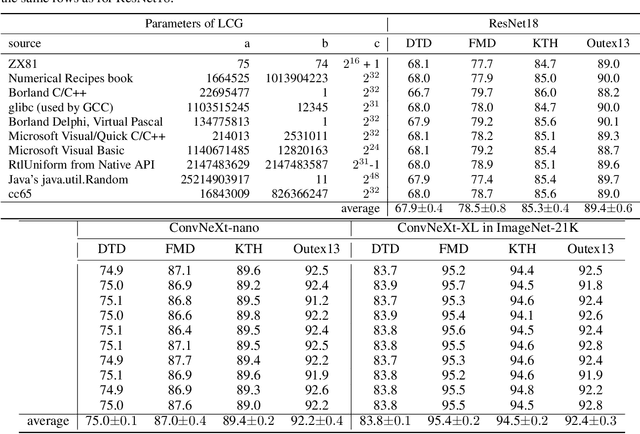
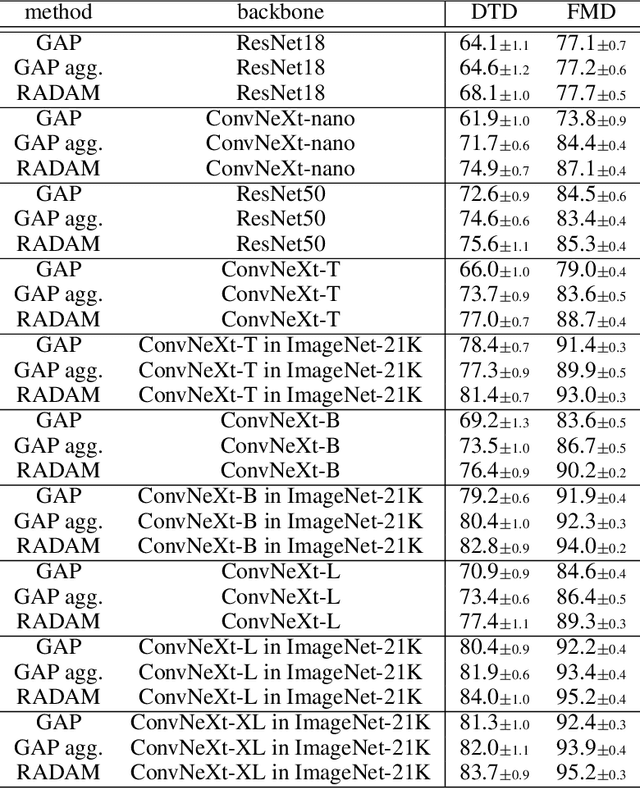
Texture analysis is a classical yet challenging task in computer vision for which deep neural networks are actively being applied. Most approaches are based on building feature aggregation modules around a pre-trained backbone and then fine-tuning the new architecture on specific texture recognition tasks. Here we propose a new method named \textbf{R}andom encoding of \textbf{A}ggregated \textbf{D}eep \textbf{A}ctivation \textbf{M}aps (RADAM) which extracts rich texture representations without ever changing the backbone. The technique consists of encoding the output at different depths of a pre-trained deep convolutional network using a Randomized Autoencoder (RAE). The RAE is trained locally to each image using a closed-form solution, and its decoder weights are used to compose a 1-dimensional texture representation that is fed into a linear SVM. This means that no fine-tuning or backpropagation is needed. We explore RADAM on several texture benchmarks and achieve state-of-the-art results with different computational budgets. Our results suggest that pre-trained backbones may not require additional fine-tuning for texture recognition if their learned representations are better encoded.