 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Answering based Clinical Text Structuring Using Pre-trained Language Model
Paper and Code
Aug 19, 2019
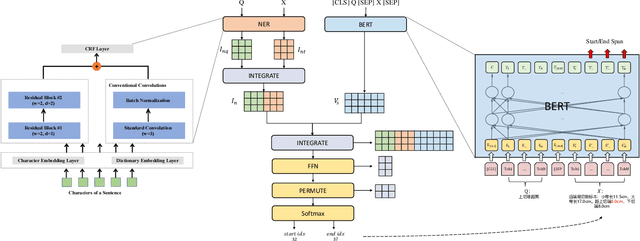

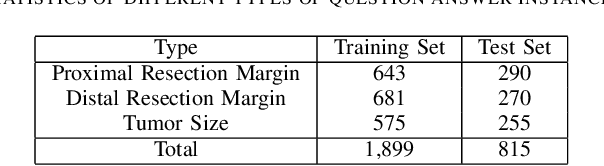
Clinical text structuring is a critical and fundamental task for clinical research. Traditional methods such as taskspecific end-to-end models and pipeline models usually suffer from the lack of dataset and error propagation. In this paper, we present a question answering based clinical text structuring (QA-CTS) task to unify different specific tasks and make dataset shareable. A novel model that aims to introduce domain-specific features (e.g., clinical named entity information) into pre-trained language model is also proposed for QA-CTS task. Experimental results on Chinese pathology reports collected from Ruijing Hospital demonstrate our presented QA-CTS task is very effective to improve the performance on specific tasks. Our proposed model also competes favorably with strong baseline models in specific tasks.