 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Minimally-Distorted Adversarial Examples
Paper and Code
Feb 20, 2018
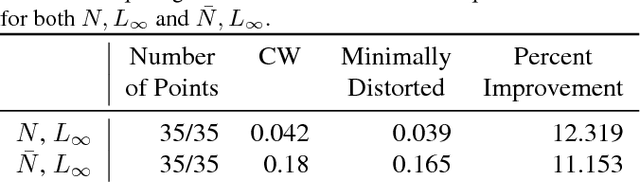
The ability to deploy neural networks in real-world, safety-critical systems is severely limited by the presence of adversarial examples: slightly perturbed inputs that are misclassified by the network. In recent years, several techniques have been proposed for increasing robustness to adversarial examples --- and yet most of these have been quickly shown to be vulnerable to future attacks. For example, over half of the defenses proposed by papers accepted at ICLR 2018 have already been broken. We propose to address this difficulty through formal verification techniques. We show how to construct provably minimally distorted adversarial examples: given an arbitrary neural network and input sample, we can construct adversarial examples which we prove are of minimal distortion. Using this approach, we demonstrate that one of the recent ICLR defense proposals, adversarial retraining, provably succeeds at increasing the distortion required to construct adversarial examples by a factor of 4.2.