 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Visual-Language Models for Efficient Video Understanding
Paper and Code
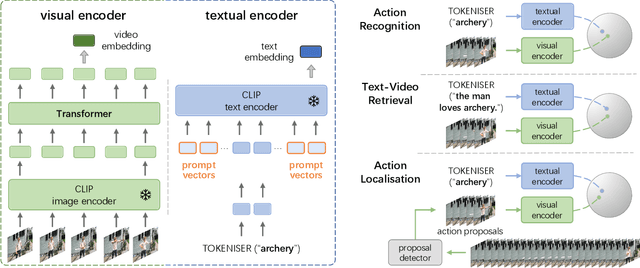


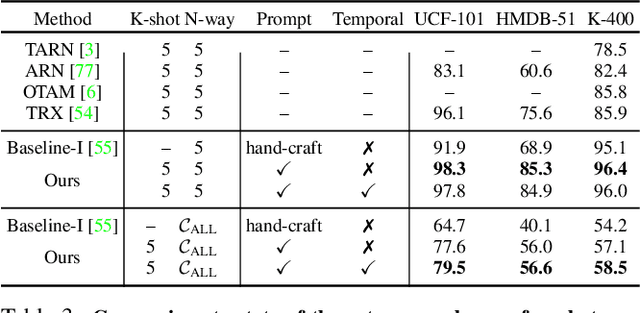
Visual-language pre-training has shown great success for learning joint visual-textual representations from large-scale web data, demonstrating remarkable ability for zero-shot generalisation. This paper presents a simple method to efficiently adapt one pre-trained visual-language model to novel tasks with minimal training, and here, we consider video understanding tasks. Specifically, we propose to optimise a few random vectors, termed as continuous prompt vectors, that convert the novel tasks into the same format as the pre-training objectives. In addition, to bridge the gap between static images and videos, temporal information is encoded with lightweight Transformers stacking on top of frame-wise visual features. Experimentally, we conduct extensive ablation studies to analyse the critical components and necessities. On 9 public benchmarks of action recognition, action localisation, and text-video retrieval, across closed-set, few-shot, open-set scenarios, we achieve competitive or state-of-the-art performance to existing methods, despite training significantly fewer parameters.