 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Backdoors in Visual Prompt Learning
Paper and Code
Oct 11, 2023
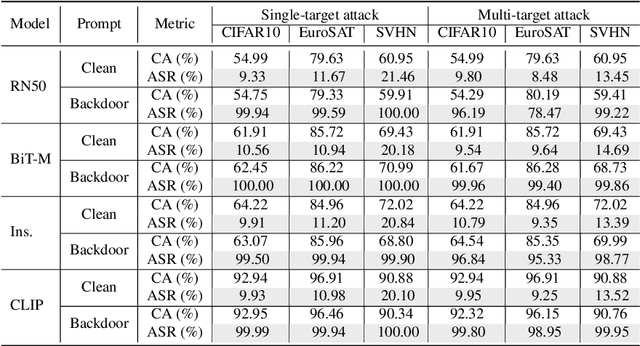
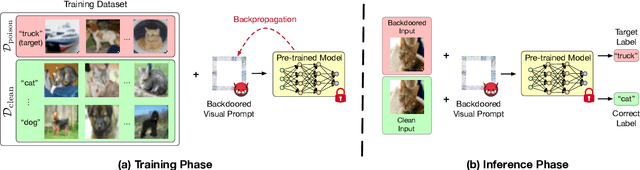
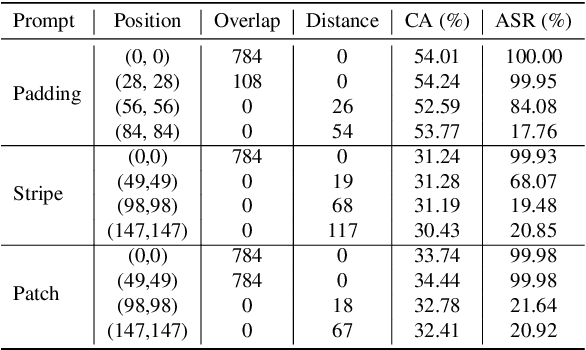
Fine-tuning large pre-trained computer vision models is infeasible for resource-limited users. Visual prompt learning (VPL) has thus emerged to provide an efficient and flexible alternative to model fine-tuning through Visual Prompt as a Service (VPPTaaS). Specifically, the VPPTaaS provider optimizes a visual prompt given downstream data, and downstream users can use this prompt together with the large pre-trained model for prediction. However, this new learning paradigm may also pose security risks when the VPPTaaS provider instead provides a malicious visual prompt. In this paper, we take the first step to explore such risks through the lens of backdoor attacks. Specifically, we propose BadVisualPrompt, a simple yet effective backdoor attack against VPL. For example, poisoning $5\%$ CIFAR10 training data leads to above $99\%$ attack success rates with only negligible model accuracy drop by $1.5\%$. In particular, we identify and then address a new technical challenge related to interactions between the backdoor trigger and visual prompt, which does not exist in conventional, model-level backdoors. Moreover, we provide in-depth analyses of seven backdoor defenses from model, prompt, and input levels. Overall, all these defenses are either ineffective or impractical to mitigate our BadVisualPrompt, implying the critical vulnerability of VPL.