 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Biomedical Embeddings from Language Models
Paper and Code

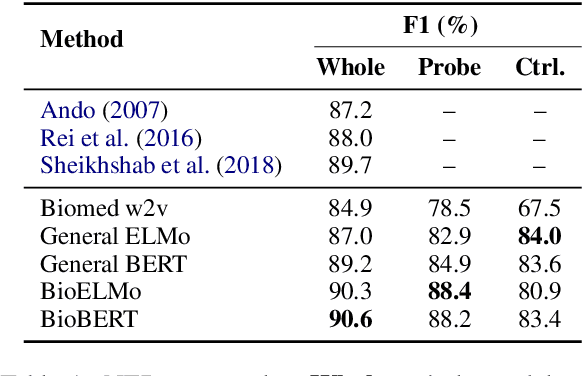
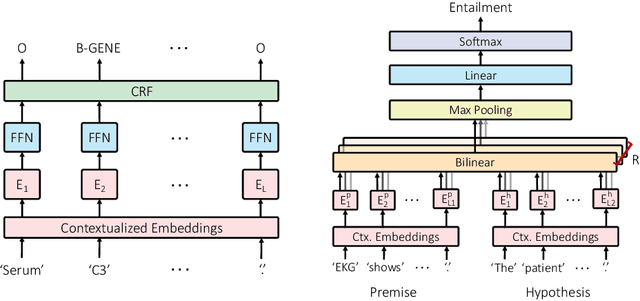
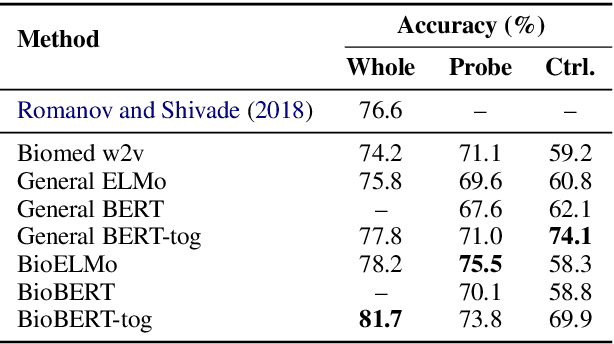
Contextualized word embeddings derived from pre-trained language models (LMs) show significant improvements on downstream NLP tasks. Pre-training on domain-specific corpora, such as biomedical articles, further improves their performance. In this paper, we conduct probing experiments to determine what additional information is carried intrinsically by the in-domain trained contextualized embeddings. For this we use the pre-trained LMs as fixed feature extractors and restrict the downstream task models to not have additional sequence modeling layers. We compare BERT, ELMo, BioBERT and BioELMo, a biomedical version of ELMo trained on 10M PubMed abstracts. Surprisingly, while fine-tuned BioBERT is better than BioELMo in biomedical NER and NLI tasks, as a fixed feature extractor BioELMo outperforms BioBERT in our probing tasks. We use visualization and nearest neighbor analysis to show that better encoding of entity-type and relational information leads to this superiority.