 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistically Sampled and Spectrally Clustered Plant Genotypes using Phenotypic Characteristics
Paper and Code
Sep 18, 2020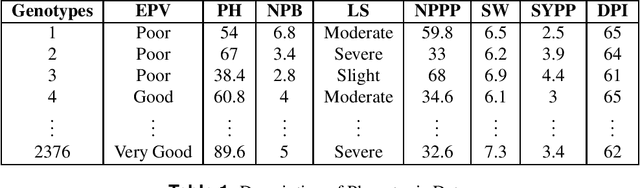
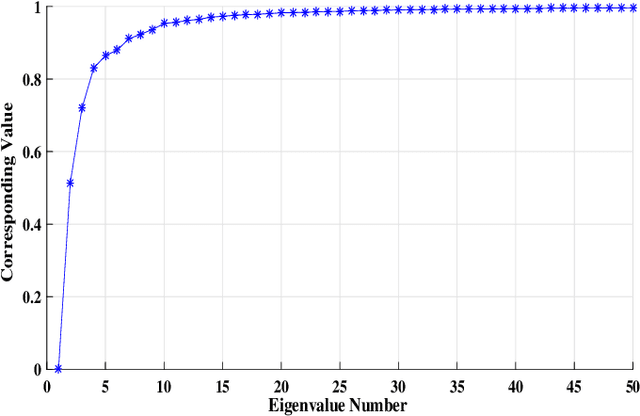
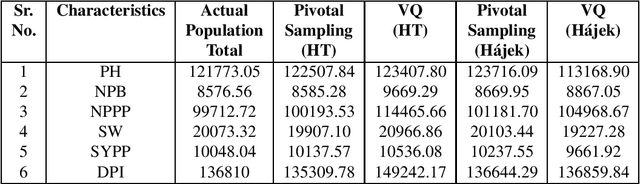
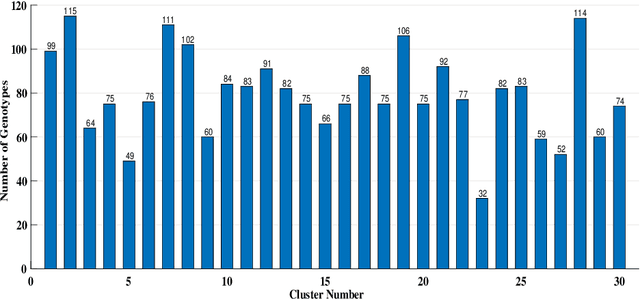
Clustering genotypes based upon their phenotypic characteristics is used to obtain diverse sets of parents that are useful in their breeding programs. The Hierarchical Clustering (HC) algorithm is the current standard in clustering of phenotypic data. This algorithm suffers from low accuracy and high computational complexity issues. To address the accuracy challenge, we propose the use of Spectral Clustering (SC) algorithm. To make the algorithm computationally cheap, we propose using sampling, specifically, Pivotal Sampling that is probability based. Since application of samplings to phenotypic data has not been explored much, for effective comparison, another sampling technique called Vector Quantization (VQ) is adapted for this data as well. VQ has recently given promising results for genome data. The novelty of our SC with Pivotal Sampling algorithm is in constructing the crucial similarity matrix for the clustering algorithm and defining probabilities for the sampling technique. Although our algorithm can be applied to any plant genotypes, we test it on the phenotypic data obtained from about 2400 Soybean genotypes. SC with Pivotal Sampling achieves substantially more accuracy (in terms of Silhouette Values) than all the other proposed competitive clustering with sampling algorithms (i.e. SC with VQ, HC with Pivotal Sampling, and HC with VQ). The complexities of our SC with Pivotal Sampling algorithm and these three variants are almost same because of the involved sampling. In addition to this, SC with Pivotal Sampling outperforms the standard HC algorithm in both accuracy and computational complexity. We experimentally show that we are up to 45% more accurate than HC in terms of clustering accuracy. The computational complexity of our algorithm is more than a magnitude lesser than HC.