 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Multigraph Modeling for Improving the Quality of Crowdsourced Affective Data
Paper and Code
Jan 06, 2017


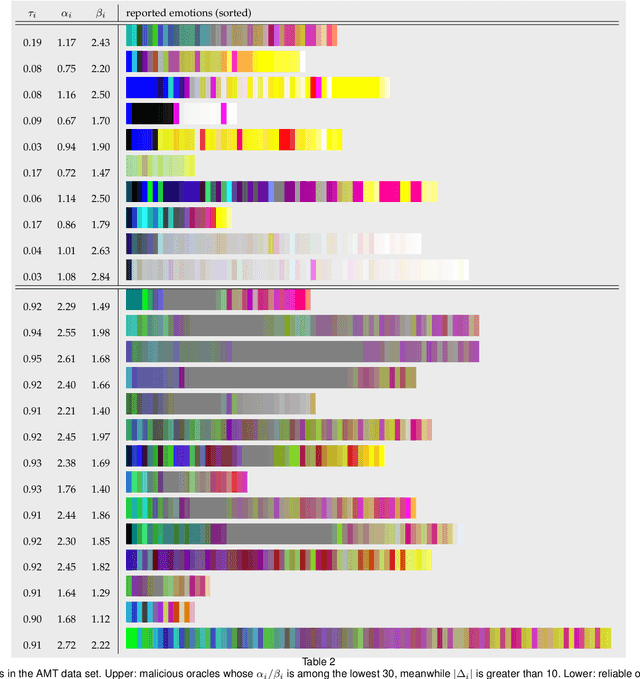
We proposed a probabilistic approach to joint modeling of participants' reliability and humans' regularity in crowdsourced affective studies. Reliability measures how likely a subject will respond to a question seriously; and regularity measures how often a human will agree with other seriously-entered responses coming from a targeted population. Crowdsourcing-based studies or experiments, which rely on human self-reported affect, pose additional challenges as compared with typical crowdsourcing studies that attempt to acquire concrete non-affective labels of objects. The reliability of participants has been massively pursued for typical non-affective crowdsourcing studies, whereas the regularity of humans in an affective experiment in its own right has not been thoroughly considered. It has been often observed that different individuals exhibit different feelings on the same test question, which does not have a sole correct response in the first place. High reliability of responses from one individual thus cannot conclusively result in high consensus across individuals. Instead, globally testing consensus of a population is of interest to investigators. Built upon the agreement multigraph among tasks and workers, our probabilistic model differentiates subject regularity from population reliability. We demonstrate the method's effectiveness for in-depth robust analysis of large-scale crowdsourced affective data, including emotion and aesthetic assessments collected by presenting visual stimuli to human subjects.