 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Stochastic Non-Convex Optimization: Adaptive Algorithms and Tighter Generalization Bounds
Paper and Code
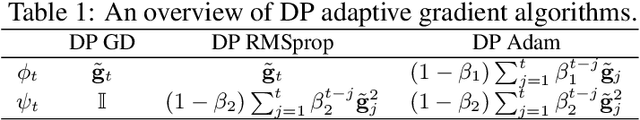
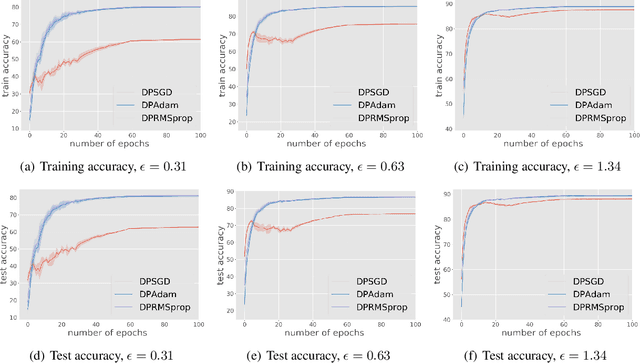

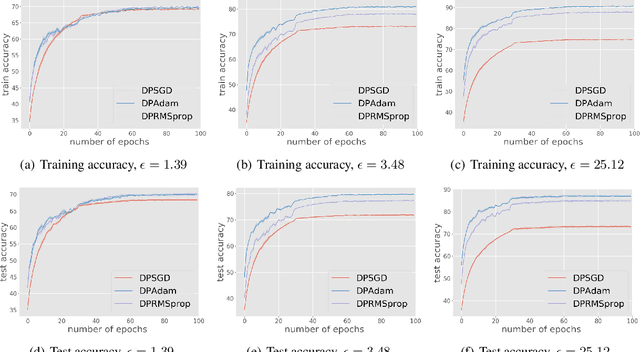
We study differentially private (DP) algorithms for stochastic non-convex optimization. In this problem, the goal is to minimize the population loss over a $p$-dimensional space given $n$ i.i.d. samples drawn from a distribution. We improve upon the population gradient bound of ${\sqrt{p}}/{\sqrt{n}}$ from prior work and obtain a sharper rate of $\sqrt[4]{p}/\sqrt{n}$. We obtain this rate by providing the first analyses on a collection of private gradient-based methods, including adaptive algorithms DP RMSProp and DP Adam. Our proof technique leverages the connection between differential privacy and adaptive data analysis to bound gradient estimation error at every iterate, which circumvents the worse generalization bound from the standard uniform convergence argument. Finally, we evaluate the proposed algorithms on two popular deep learning tasks and demonstrate the empirical advantages of DP adaptive gradient methods over standard DP SGD.