 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Distributed SVD via Federated Power
Paper and Code
Mar 01, 2021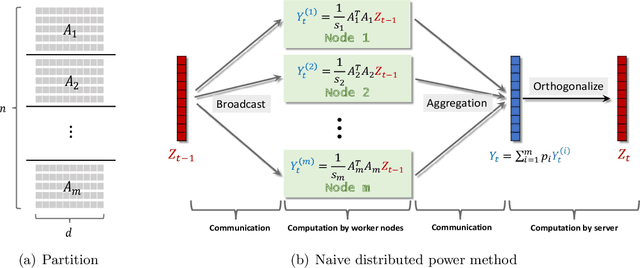
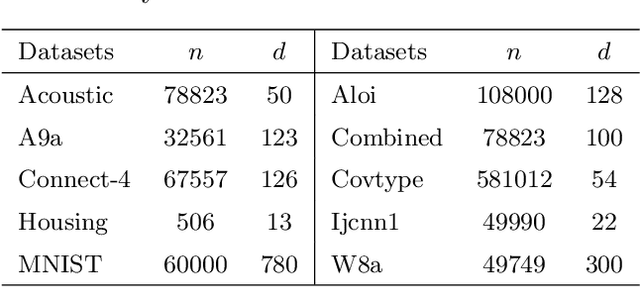
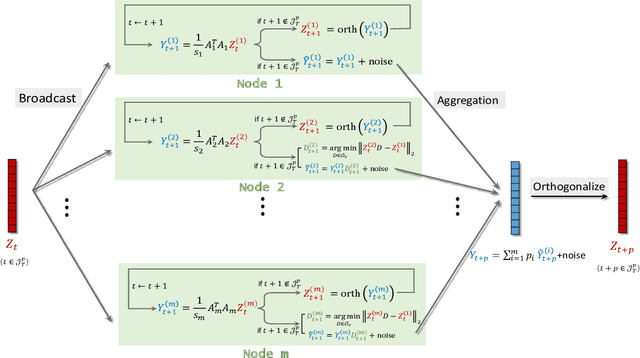
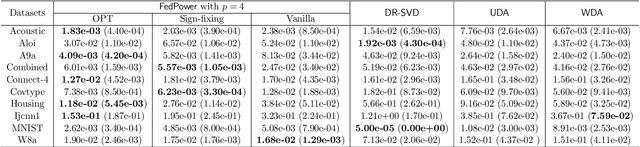
Singular value decomposition (SVD) is one of the most fundamental tools in machine learning and statistics.The modern machine learning community usually assumes that data come from and belong to small-scale device users. The low communication and computation power of such devices, and the possible privacy breaches of users' sensitive data make the computation of SVD challenging. Federated learning (FL) is a paradigm enabling a large number of devices to jointly learn a model in a communication-efficient way without data sharing. In the FL framework, we develop a class of algorithms called FedPower for the computation of partial SVD in the modern setting. Based on the well-known power method, the local devices alternate between multiple local power iterations and one global aggregation to improve communication efficiency. In the aggregation, we propose to weight each local eigenvector matrix with Orthogonal Procrustes Transformation (OPT). Considering the practical stragglers' effect, the aggregation can be fully participated or partially participated, where for the latter we propose two sampling and aggregation schemes. Further, to ensure strong privacy protection, we add Gaussian noise whenever the communication happens by adopting the notion of differential privacy (DP). We theoretically show the convergence bound for FedPower. The resulting bound is interpretable with each part corresponding to the effect of Gaussian noise, parallelization, and random sampling of devices, respectively. We also conduct experiments to demonstrate the merits of FedPower. In particular, the local iterations not only improve communication efficiency but also reduce the chance of privacy breaches.