 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrisoners of Their Own Devices: How Models Induce Data Bias in Performative Prediction
Paper and Code
Jun 27, 2022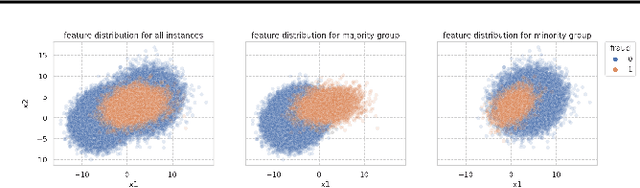


The unparalleled ability of machine learning algorithms to learn patterns from data also enables them to incorporate biases embedded within. A biased model can then make decisions that disproportionately harm certain groups in society. Much work has been devoted to measuring unfairness in static ML environments, but not in dynamic, performative prediction ones, in which most real-world use cases operate. In the latter, the predictive model itself plays a pivotal role in shaping the distribution of the data. However, little attention has been heeded to relating unfairness to these interactions. Thus, to further the understanding of unfairness in these settings, we propose a taxonomy to characterize bias in the data, and study cases where it is shaped by model behaviour. Using a real-world account opening fraud detection case study as an example, we study the dangers to both performance and fairness of two typical biases in performative prediction: distribution shifts, and the problem of selective labels.