 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefix-to-SQL: Text-to-SQL Generation from Incomplete User Questions
Paper and Code
Sep 30, 2021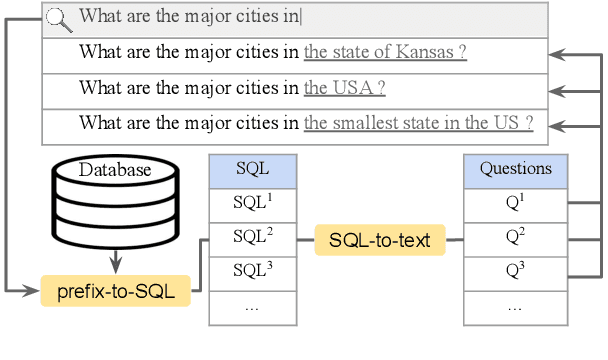

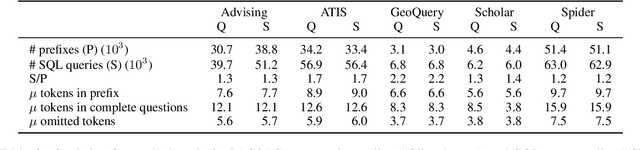
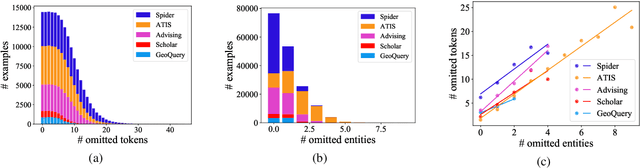
Existing text-to-SQL research only considers complete questions as the input, but lay-users might strive to formulate a complete question. To build a smarter natural language interface to database systems (NLIDB) that also processes incomplete questions, we propose a new task, prefix-to-SQL which takes question prefix from users as the input and predicts the intended SQL. We construct a new benchmark called PAGSAS that contains 124K user question prefixes and the intended SQL for 5 sub-tasks Advising, GeoQuery, Scholar, ATIS, and Spider. Additionally, we propose a new metric SAVE to measure how much effort can be saved by users. Experimental results show that PAGSAS is challenging even for strong baseline models such as T5. As we observe the difficulty of prefix-to-SQL is related to the number of omitted tokens, we incorporate curriculum learning of feeding examples with an increasing number of omitted tokens. This improves scores on various sub-tasks by as much as 9% recall scores on sub-task GeoQuery in PAGSAS.