 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting COVID-19 Patient Shielding: A Comprehensive Study
Paper and Code
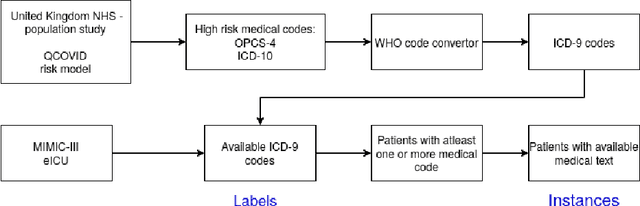
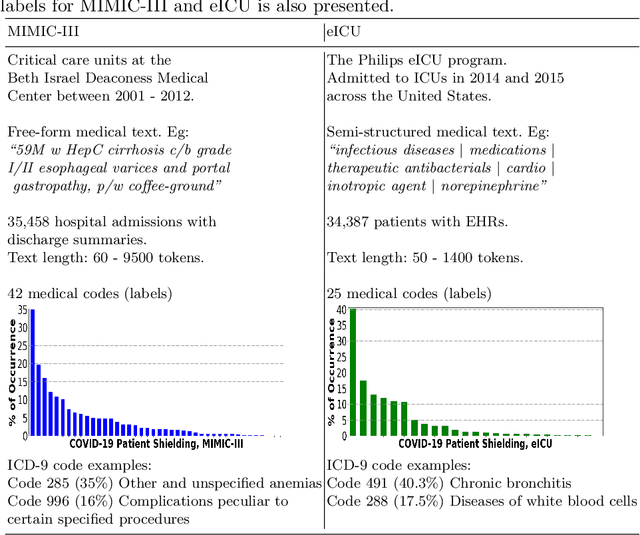
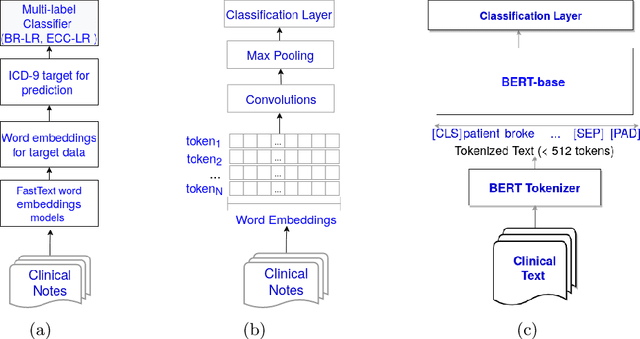

There are many ways machine learning and big data analytics are used in the fight against the COVID-19 pandemic, including predictions, risk management, diagnostics, and prevention. This study focuses on predicting COVID-19 patient shielding -- identifying and protecting patients who are clinically extremely vulnerable from coronavirus. This study focuses on techniques used for the multi-label classification of medical text. Using the information published by the United Kingdom NHS and the World Health Organisation, we present a novel approach to predicting COVID-19 patient shielding as a multi-label classification problem. We use publicly available, de-identified ICU medical text data for our experiments. The labels are derived from the published COVID-19 patient shielding data. We present an extensive comparison across 12 multi-label classifiers from the simple binary relevance to neural networks and the most recent transformers. To the best of our knowledge this is the first comprehensive study, where such a range of multi-label classifiers for medical text are considered. We highlight the benefits of various approaches, and argue that, for the task at hand, both predictive accuracy and processing time are essential.