 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOS-BERT: Point Cloud One-Stage BERT Pre-Training
Paper and Code
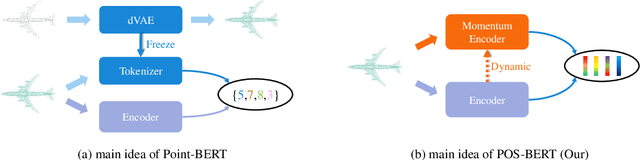


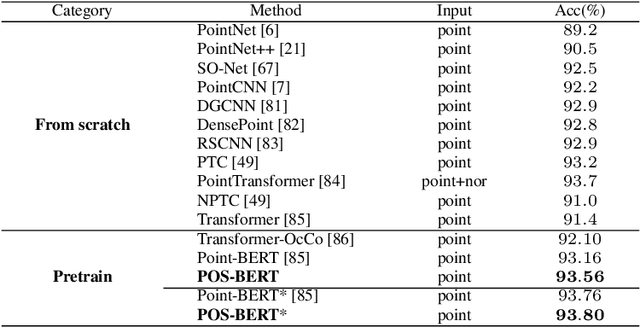
Recently, the pre-training paradigm combining Transformer and masked language modeling has achieved tremendous success in NLP, images, and point clouds, such as BERT. However, directly extending BERT from NLP to point clouds requires training a fixed discrete Variational AutoEncoder (dVAE) before pre-training, which results in a complex two-stage method called Point-BERT. Inspired by BERT and MoCo, we propose POS-BERT, a one-stage BERT pre-training method for point clouds. Specifically, we use the mask patch modeling (MPM) task to perform point cloud pre-training, which aims to recover masked patches information under the supervision of the corresponding tokenizer output. Unlike Point-BERT, its tokenizer is extra-trained and frozen. We propose to use the dynamically updated momentum encoder as the tokenizer, which is updated and outputs the dynamic supervision signal along with the training process. Further, in order to learn high-level semantic representation, we combine contrastive learning to maximize the class token consistency between different transformation point clouds. Extensive experiments have demonstrated that POS-BERT can extract high-quality pre-training features and promote downstream tasks to improve performance. Using the pre-training model without any fine-tuning to extract features and train linear SVM on ModelNet40, POS-BERT achieves the state-of-the-art classification accuracy, which exceeds Point-BERT by 3.5\%. In addition, our approach has significantly improved many downstream tasks, such as fine-tuned classification, few-shot classification, part segmentation. The code and trained-models will be available at: \url{https://github.com/fukexue/POS-BERT}.