 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoP-Net: Pose over Parts Network for Multi-Person 3D Pose Estimation from a Depth Image
Paper and Code
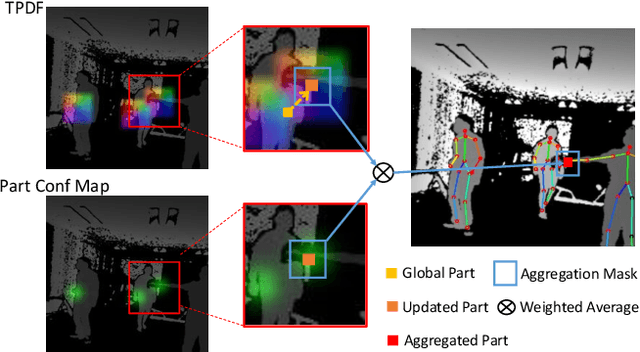
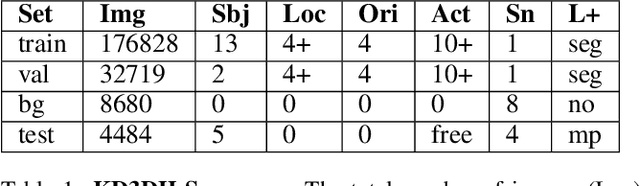

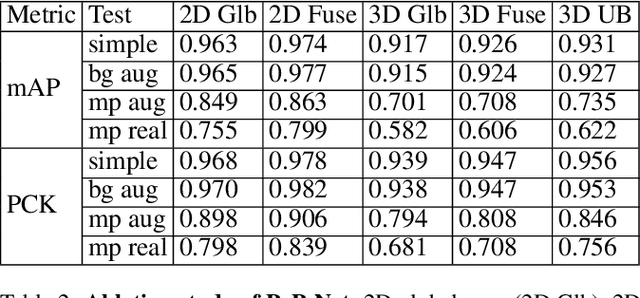
In this paper, a real-time method called PoP-Net is proposed to predict multi-person 3D poses from a depth image. PoP-Net learns to predict bottom-up part detection maps and top-down global poses in a single-shot framework. A simple and effective fusion process is applied to fuse the global poses and part detection. Specifically, a new part-level representation, called Truncated Part Displacement Field (TPDF), is introduced. It drags low-precision global poses towards more accurate part locations while maintaining the advantage of global poses in handling severe occlusion and truncation cases. A mode selection scheme is developed to automatically resolve the conflict between global poses and local detection. Finally, due to the lack of high-quality depth datasets for developing and evaluating multi-person 3D pose estimation methods, a comprehensive depth dataset with 3D pose labels is released. The dataset is designed to enable effective multi-person and background data augmentation such that the developed models are more generalizable towards uncontrolled real-world multi-person scenarios. We show that PoP-Net has significant advantages in efficiency for multi-person processing and achieves the state-of-the-art results both on the released challenging dataset and on the widely used ITOP dataset.