 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy-Based Bayesian Experimental Design for Non-Differentiable Implicit Models
Paper and Code
Mar 08, 2022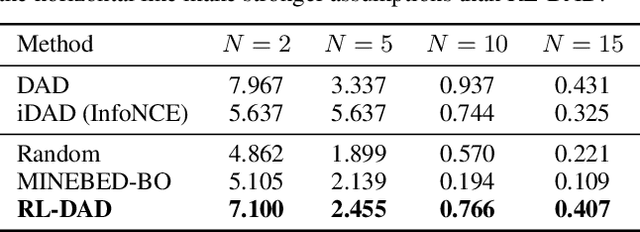
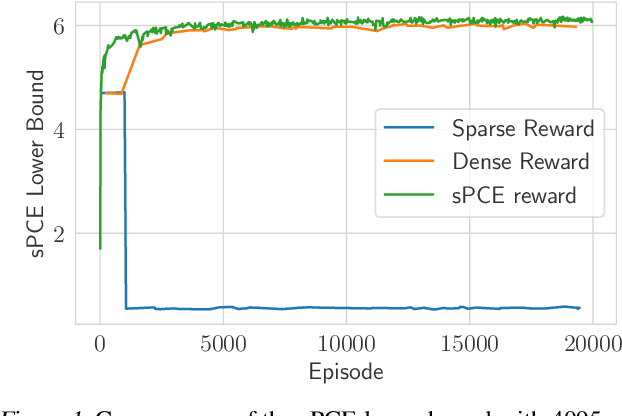
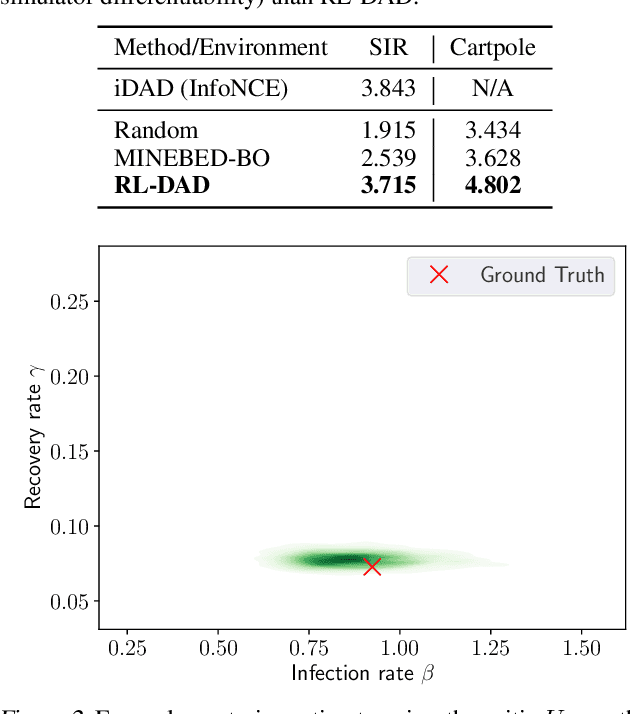
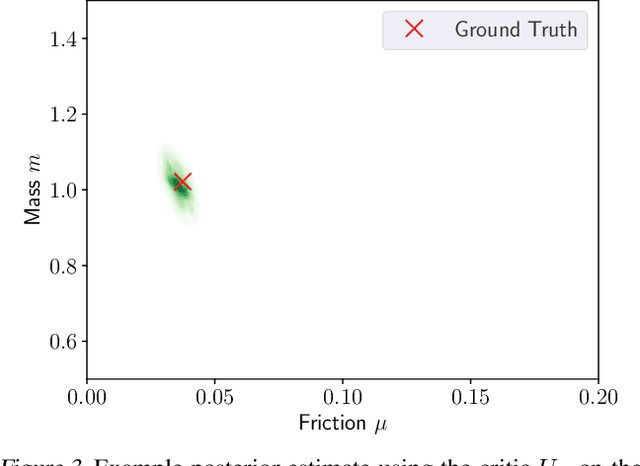
For applications in healthcare, physics, energy, robotics, and many other fields, designing maximally informative experiments is valuable, particularly when experiments are expensive, time-consuming, or pose safety hazards. While existing approaches can sequentially design experiments based on prior observation history, many of these methods do not extend to implicit models, where simulation is possible but computing the likelihood is intractable. Furthermore, they often require either significant online computation during deployment or a differentiable simulation system. We introduce Reinforcement Learning for Deep Adaptive Design (RL-DAD), a method for simulation-based optimal experimental design for non-differentiable implicit models. RL-DAD extends prior work in policy-based Bayesian Optimal Experimental Design (BOED) by reformulating it as a Markov Decision Process with a reward function based on likelihood-free information lower bounds, which is used to learn a policy via deep reinforcement learning. The learned design policy maps prior histories to experiment designs offline and can be quickly deployed during online execution. We evaluate RL-DAD and find that it performs competitively with baselines on three benchmarks.