 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint-aware Interaction and CNN-induced Refinement Network for RGB-D Salient Object Detection
Paper and Code



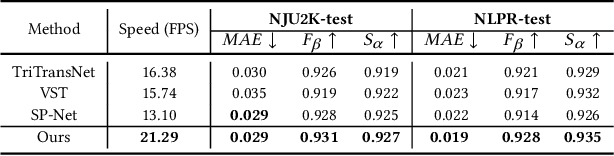
By integrating complementary information from RGB image and depth map, the ability of salient object detection (SOD) for complex and challenging scenes can be improved. In recent years, the important role of Convolutional Neural Networks (CNNs) in feature extraction and cross-modality interaction has been fully explored, but it is still insufficient in modeling global long-range dependencies of self-modality and cross-modality. To this end, we introduce CNNs-assisted Transformer architecture and propose a novel RGB-D SOD network with Point-aware Interaction and CNN-induced Refinement (PICR-Net). On the one hand, considering the prior correlation between RGB modality and depth modality, an attention-triggered cross-modality point-aware interaction (CmPI) module is designed to explore the feature interaction of different modalities with positional constraints. On the other hand, in order to alleviate the block effect and detail destruction problems brought by the Transformer naturally, we design a CNN-induced refinement (CNNR) unit for content refinement and supplementation. Extensive experiments on five RGB-D SOD datasets show that the proposed network achieves competitive results in both quantitative and qualitative comparisons.