 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLLaMa: An Open-source Large Language Model for Plant Science
Paper and Code

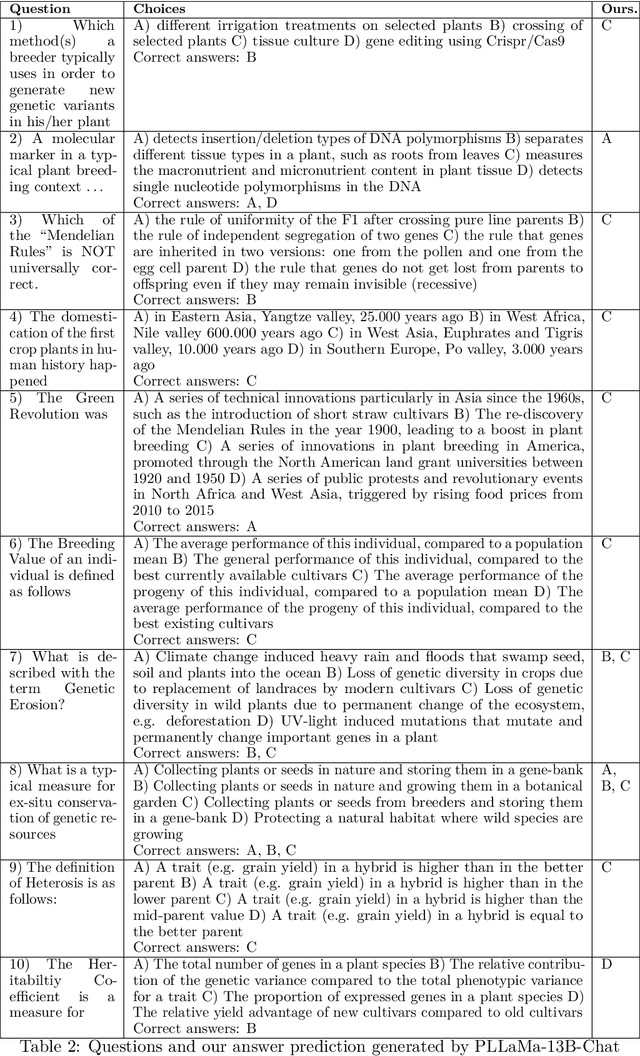
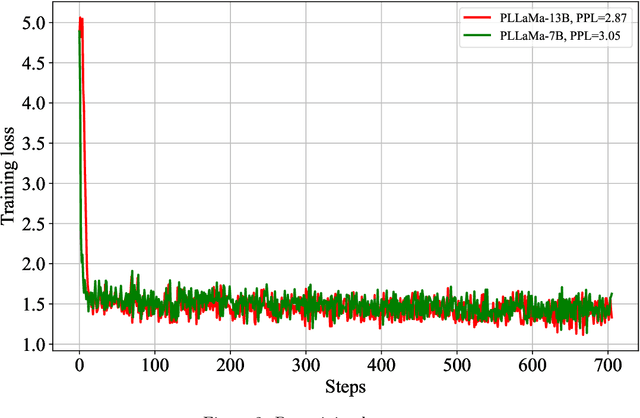
Large Language Models (LLMs) have exhibited remarkable capabilities in understanding and interacting with natural language across various sectors. However, their effectiveness is limited in specialized areas requiring high accuracy, such as plant science, due to a lack of specific expertise in these fields. This paper introduces PLLaMa, an open-source language model that evolved from LLaMa-2. It's enhanced with a comprehensive database, comprising more than 1.5 million scholarly articles in plant science. This development significantly enriches PLLaMa with extensive knowledge and proficiency in plant and agricultural sciences. Our initial tests, involving specific datasets related to plants and agriculture, show that PLLaMa substantially improves its understanding of plant science-related topics. Moreover, we have formed an international panel of professionals, including plant scientists, agricultural engineers, and plant breeders. This team plays a crucial role in verifying the accuracy of PLLaMa's responses to various academic inquiries, ensuring its effective and reliable application in the field. To support further research and development, we have made the model's checkpoints and source codes accessible to the scientific community. These resources are available for download at \url{https://github.com/Xianjun-Yang/PLLaMa}.