 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIM-QAT: Neural Network Quantization for Processing-In-Memory (PIM) Systems
Paper and Code
Sep 18, 2022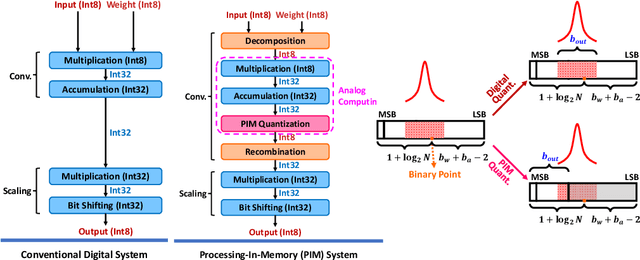

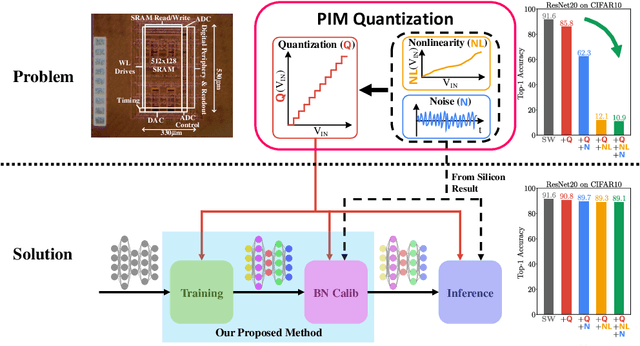

Processing-in-memory (PIM), an increasingly studied neuromorphic hardware, promises orders of energy and throughput improvements for deep learning inference. Leveraging the massively parallel and efficient analog computing inside memories, PIM circumvents the bottlenecks of data movements in conventional digital hardware. However, an extra quantization step (i.e. PIM quantization), typically with limited resolution due to hardware constraints, is required to convert the analog computing results into digital domain. Meanwhile, non-ideal effects extensively exist in PIM quantization because of the imperfect analog-to-digital interface, which further compromises the inference accuracy. In this paper, we propose a method for training quantized networks to incorporate PIM quantization, which is ubiquitous to all PIM systems. Specifically, we propose a PIM quantization aware training (PIM-QAT) algorithm, and introduce rescaling techniques during backward and forward propagation by analyzing the training dynamics to facilitate training convergence. We also propose two techniques, namely batch normalization (BN) calibration and adjusted precision training, to suppress the adverse effects of non-ideal linearity and stochastic thermal noise involved in real PIM chips. Our method is validated on three mainstream PIM decomposition schemes, and physically on a prototype chip. Comparing with directly deploying conventionally trained quantized model on PIM systems, which does not take into account this extra quantization step and thus fails, our method provides significant improvement. It also achieves comparable inference accuracy on PIM systems as that of conventionally quantized models on digital hardware, across CIFAR10 and CIFAR100 datasets using various network depths for the most popular network topology.