 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Optimization for Variable Bitwidth Federated Learning in Wireless Networks
Paper and Code
Sep 21, 2022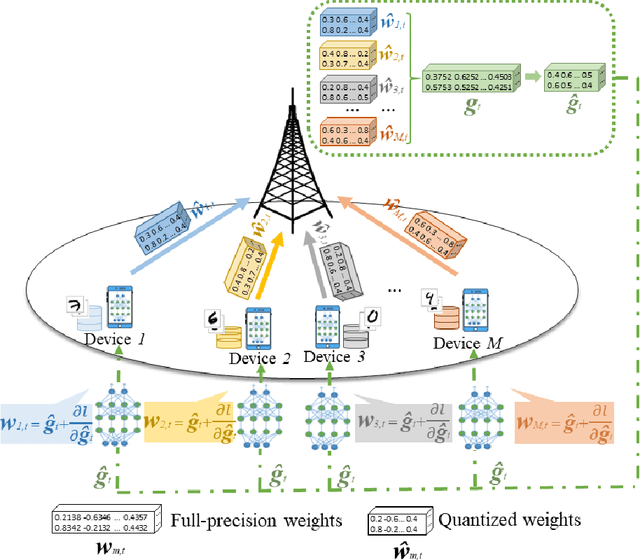
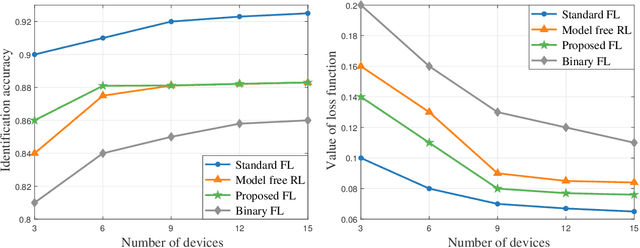
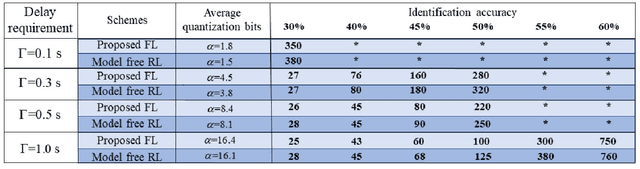
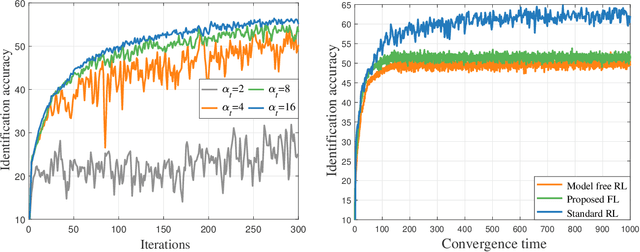
This paper considers improving wireless communication and computation efficiency in federated learning (FL) via model quantization. In the proposed bitwidth FL scheme, edge devices train and transmit quantized versions of their local FL model parameters to a coordinating server, which, in turn, aggregates them into a quantized global model and synchronizes the devices. The goal is to jointly determine the bitwidths employed for local FL model quantization and the set of devices participating in FL training at each iteration. This problem is posed as an optimization problem whose goal is to minimize the training loss of quantized FL under a per-iteration device sampling budget and delay requirement. To derive the solution, an analytical characterization is performed in order to show how the limited wireless resources and induced quantization errors affect the performance of the proposed FL method. The analytical results show that the improvement of FL training loss between two consecutive iterations depends on the device selection and quantization scheme as well as on several parameters inherent to the model being learned. Given linear regression-based estimates of these model properties, it is shown that the FL training process can be described as a Markov decision process (MDP), and, then, a model-based reinforcement learning (RL) method is proposed to optimize action selection over iterations. Compared to model-free RL, this model-based RL approach leverages the derived mathematical characterization of the FL training process to discover an effective device selection and quantization scheme without imposing additional device communication overhead. Simulation results show that the proposed FL algorithm can reduce 29% and 63% convergence time compared to a model free RL method and the standard FL method, respectively.