 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParity Crowdsourcing for Cooperative Labeling
Paper and Code
Sep 04, 2018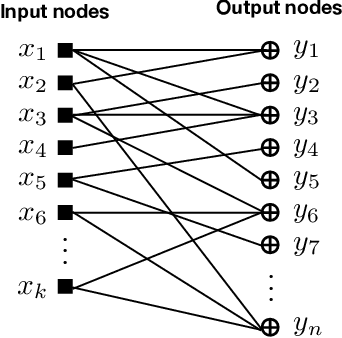
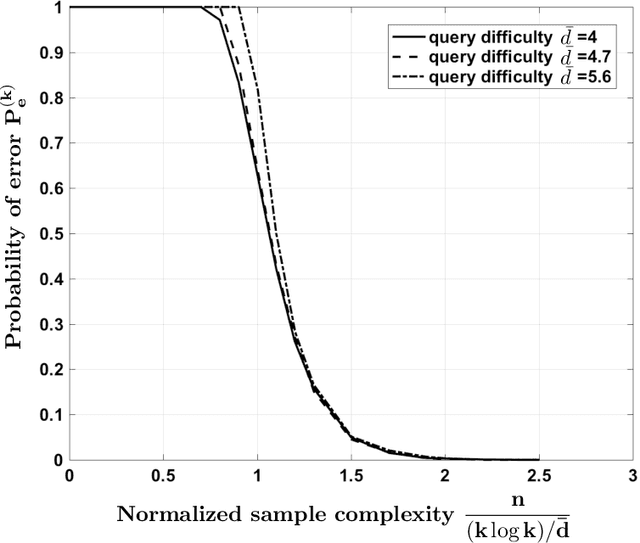
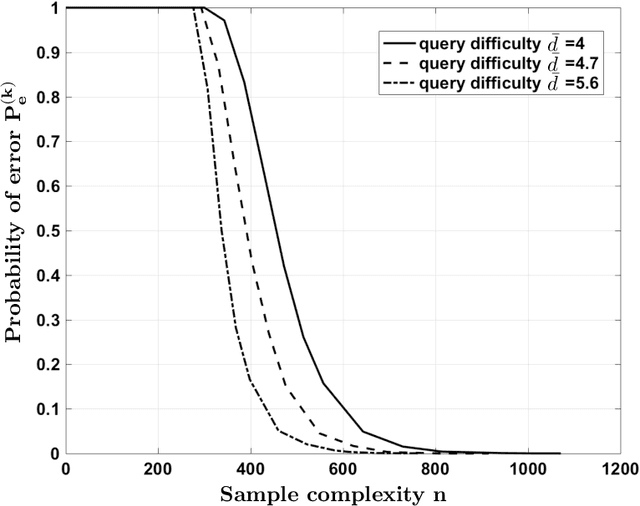
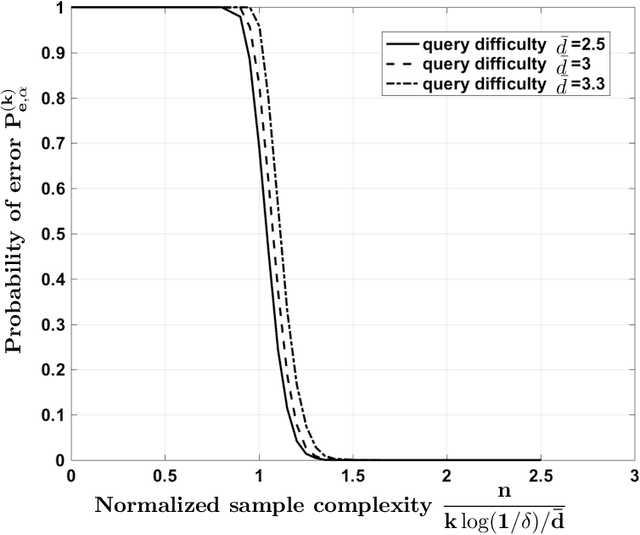
Consider a database of $k$ objects, e.g., a set of videos, where each object has a binary attribute, e.g., a video's suitability for children. The attributes of the objects are to be determined under a crowdsourcing model: a worker is queried about the labels of a chosen subset of objects and either responds with a correct binary answer or declines to respond. Here we propose a parity response model: the worker is asked to check whether the number of objects having a given attribute in the chosen subset is even or odd. For example, if the subset includes two objects, the worker checks whether the two belong to the same class or not. We propose a method for designing the sequence of subsets of objects to be queried so that the attributes of the objects can be identified with high probability using few ($n$) answers. The method is based on an analogy to the design of Fountain codes for erasure channels. We define the query difficulty $\bar{d}$ as the average size of the query subsets and we define the sample complexity $n$ as the minimum number of collected answers required to attain a given recovery accuracy. We obtain fundamental tradeoffs between recovery accuracy, query difficulty, and sample complexity. In particular, the necessary and sufficient sample complexity required for recovering all $k$ attributes with high probability is $n = c_0 \max\{k, (k \log k)/\bar{d}\}$ and the sample complexity for recovering a fixed proportion $(1-\delta)k$ of the attributes for $\delta=o(1)$ is $n = c_1\max\{k, (k \log(1/\delta))/\bar{d}\}$, where $c_0, c_1>0$.