 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Gaussian Process Regression for Big Data: Low-Rank Representation Meets Markov Approximation
Paper and Code
Nov 17, 2014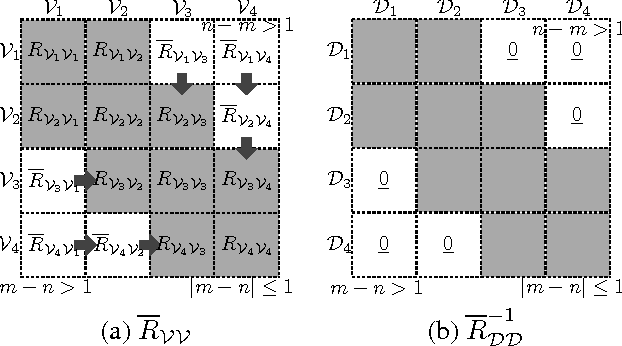


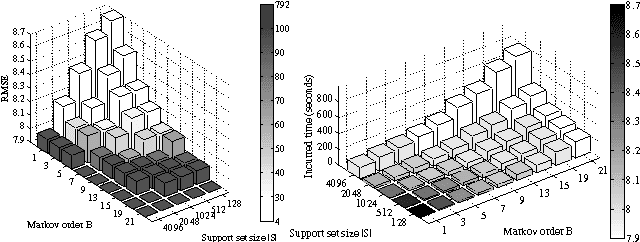
The expressive power of a Gaussian process (GP) model comes at a cost of poor scalability in the data size. To improve its scalability, this paper presents a low-rank-cum-Markov approximation (LMA) of the GP model that is novel in leveraging the dual computational advantages stemming from complementing a low-rank approximate representation of the full-rank GP based on a support set of inputs with a Markov approximation of the resulting residual process; the latter approximation is guaranteed to be closest in the Kullback-Leibler distance criterion subject to some constraint and is considerably more refined than that of existing sparse GP models utilizing low-rank representations due to its more relaxed conditional independence assumption (especially with larger data). As a result, our LMA method can trade off between the size of the support set and the order of the Markov property to (a) incur lower computational cost than such sparse GP models while achieving predictive performance comparable to them and (b) accurately represent features/patterns of any scale. Interestingly, varying the Markov order produces a spectrum of LMAs with PIC approximation and full-rank GP at the two extremes. An advantage of our LMA method is that it is amenable to parallelization on multiple machines/cores, thereby gaining greater scalability. Empirical evaluation on three real-world datasets in clusters of up to 32 computing nodes shows that our centralized and parallel LMA methods are significantly more time-efficient and scalable than state-of-the-art sparse and full-rank GP regression methods while achieving comparable predictive performances.