 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOV-SCAN: Semantically Consistent Alignment for Novel Object Discovery in Open-Vocabulary 3D Object Detection
Paper and Code
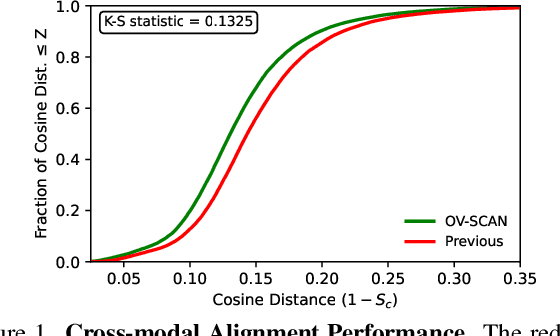
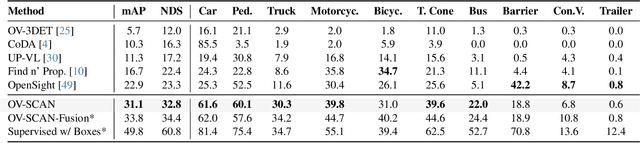
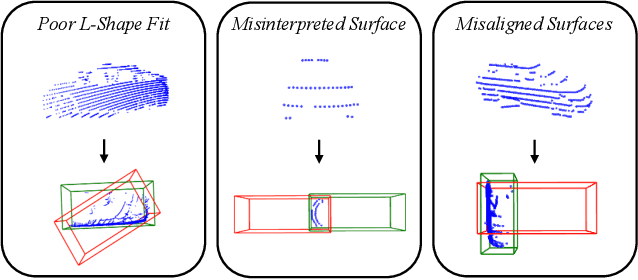
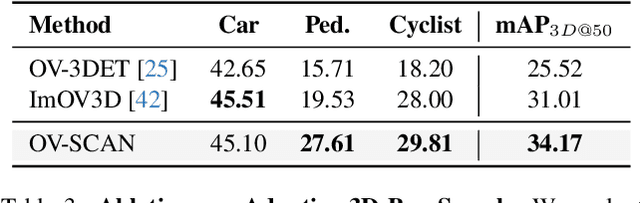
Open-vocabulary 3D object detection for autonomous driving aims to detect novel objects beyond the predefined training label sets in point cloud scenes. Existing approaches achieve this by connecting traditional 3D object detectors with vision-language models (VLMs) to regress 3D bounding boxes for novel objects and perform open-vocabulary classification through cross-modal alignment between 3D and 2D features. However, achieving robust cross-modal alignment remains a challenge due to semantic inconsistencies when generating corresponding 3D and 2D feature pairs. To overcome this challenge, we present OV-SCAN, an Open-Vocabulary 3D framework that enforces Semantically Consistent Alignment for Novel object discovery. OV-SCAN employs two core strategies: discovering precise 3D annotations and filtering out low-quality or corrupted alignment pairs (arising from 3D annotation, occlusion-induced, or resolution-induced noise). Extensive experiments on the nuScenes dataset demonstrate that OV-SCAN achieves state-of-the-art performance.