 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOtterHD: A High-Resolution Multi-modality Model
Paper and Code

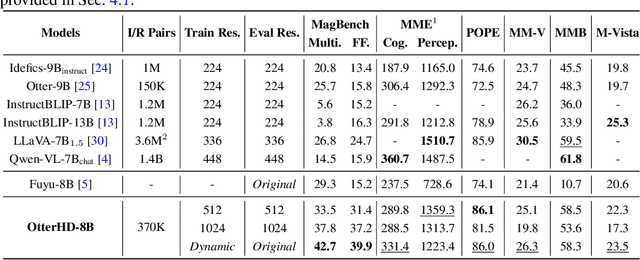


In this paper, we present OtterHD-8B, an innovative multimodal model evolved from Fuyu-8B, specifically engineered to interpret high-resolution visual inputs with granular precision. Unlike conventional models that are constrained by fixed-size vision encoders, OtterHD-8B boasts the ability to handle flexible input dimensions, ensuring its versatility across various inference requirements. Alongside this model, we introduce MagnifierBench, an evaluation framework designed to scrutinize models' ability to discern minute details and spatial relationships of small objects. Our comparative analysis reveals that while current leading models falter on this benchmark, OtterHD-8B, particularly when directly processing high-resolution inputs, outperforms its counterparts by a substantial margin. The findings illuminate the structural variances in visual information processing among different models and the influence that the vision encoders' pre-training resolution disparities have on model effectiveness within such benchmarks. Our study highlights the critical role of flexibility and high-resolution input capabilities in large multimodal models and also exemplifies the potential inherent in the Fuyu architecture's simplicity for handling complex visual data.