 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization Landscape of Policy Gradient Methods for Discrete-time Static Output Feedback
Paper and Code
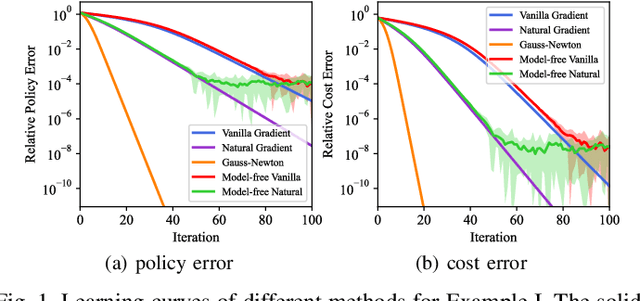
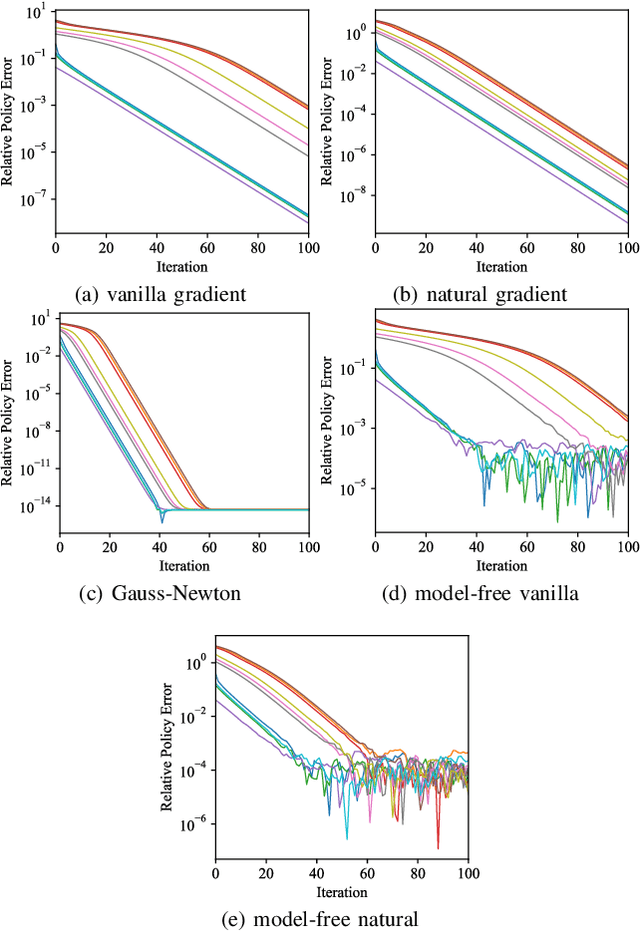
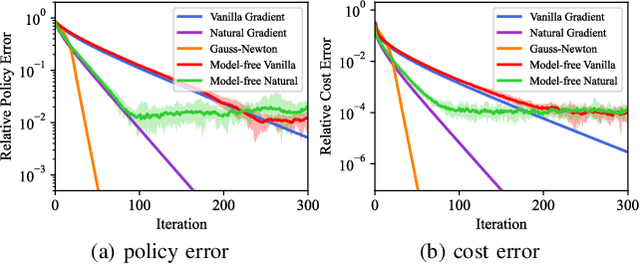
In recent times, significant advancements have been made in delving into the optimization landscape of policy gradient methods for achieving optimal control in linear time-invariant (LTI) systems. Compared with state-feedback control, output-feedback control is more prevalent since the underlying state of the system may not be fully observed in many practical settings. This paper analyzes the optimization landscape inherent to policy gradient methods when applied to static output feedback (SOF) control in discrete-time LTI systems subject to quadratic cost. We begin by establishing crucial properties of the SOF cost, encompassing coercivity, L-smoothness, and M-Lipschitz continuous Hessian. Despite the absence of convexity, we leverage these properties to derive novel findings regarding convergence (and nearly dimension-free rate) to stationary points for three policy gradient methods, including the vanilla policy gradient method, the natural policy gradient method, and the Gauss-Newton method. Moreover, we provide proof that the vanilla policy gradient method exhibits linear convergence towards local minima when initialized near such minima. The paper concludes by presenting numerical examples that validate our theoretical findings. These results not only characterize the performance of gradient descent for optimizing the SOF problem but also provide insights into the effectiveness of general policy gradient methods within the realm of reinforcement learning.