 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization for Medical Image Segmentation: Theory and Practice when evaluating with Dice Score or Jaccard Index
Paper and Code
Oct 26, 2020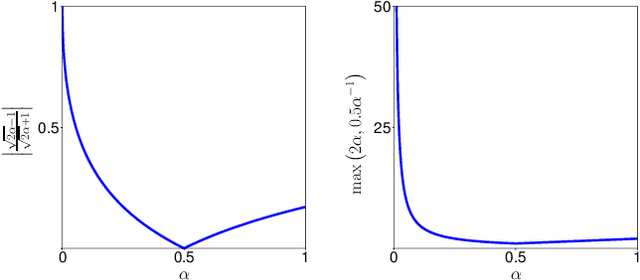
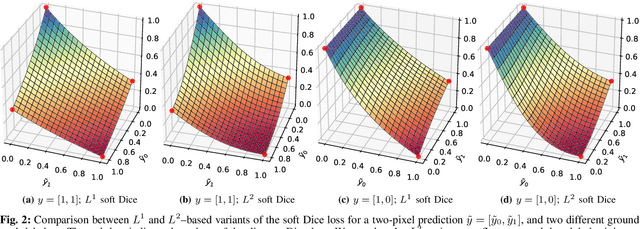
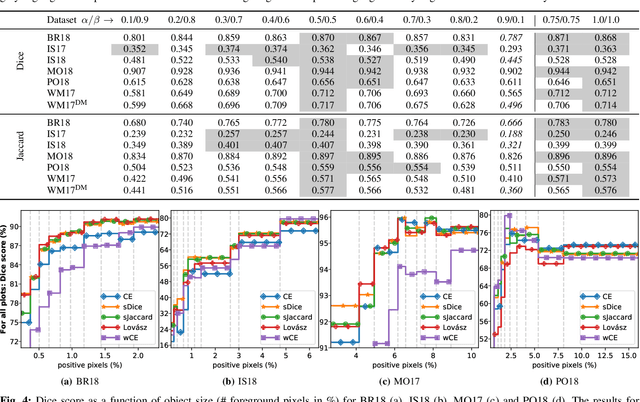
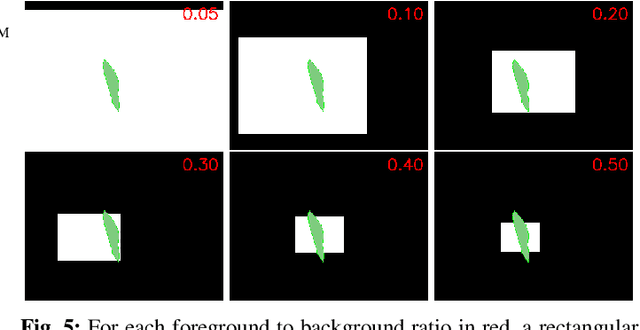
In many medical imaging and classical computer vision tasks, the Dice score and Jaccard index are used to evaluate the segmentation performance. Despite the existence and great empirical success of metric-sensitive losses, i.e. relaxations of these metrics such as soft Dice, soft Jaccard and Lovasz-Softmax, many researchers still use per-pixel losses, such as (weighted) cross-entropy to train CNNs for segmentation. Therefore, the target metric is in many cases not directly optimized. We investigate from a theoretical perspective, the relation within the group of metric-sensitive loss functions and question the existence of an optimal weighting scheme for weighted cross-entropy to optimize the Dice score and Jaccard index at test time. We find that the Dice score and Jaccard index approximate each other relatively and absolutely, but we find no such approximation for a weighted Hamming similarity. For the Tversky loss, the approximation gets monotonically worse when deviating from the trivial weight setting where soft Tversky equals soft Dice. We verify these results empirically in an extensive validation on six medical segmentation tasks and can confirm that metric-sensitive losses are superior to cross-entropy based loss functions in case of evaluation with Dice Score or Jaccard Index. This further holds in a multi-class setting, and across different object sizes and foreground/background ratios. These results encourage a wider adoption of metric-sensitive loss functions for medical segmentation tasks where the performance measure of interest is the Dice score or Jaccard index.