Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOperA: Attention-Regularized Transformers for Surgical Phase Recognition
Paper and Code
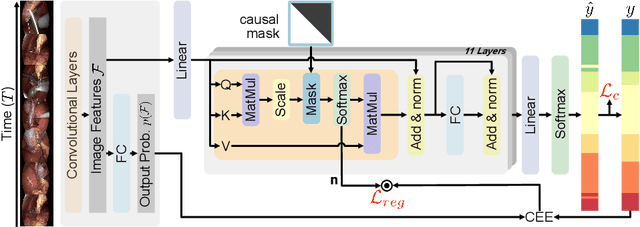
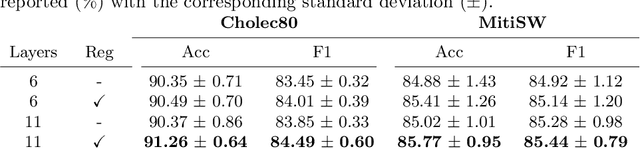


In this paper we introduce OperA, a transformer-based model that accurately predicts surgical phases from long video sequences. A novel attention regularization loss encourages the model to focus on high-quality frames during training. Moreover, the attention weights are utilized to identify characteristic high attention frames for each surgical phase, which could further be used for surgery summarization. OperA is thoroughly evaluated on two datasets of laparoscopic cholecystectomy videos, outperforming various state-of-the-art temporal refinement approaches.
* 10 pages, 3 figures
View paper on