 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-element Batch Training by Moving Window
Paper and Code

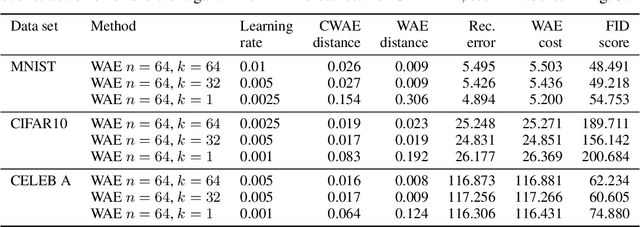

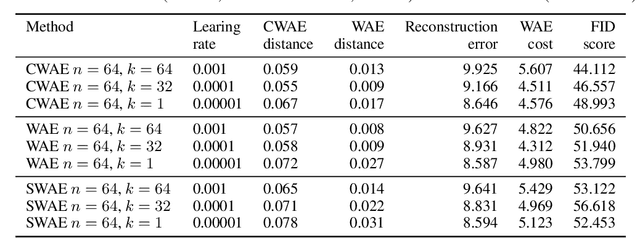
Several deep models, esp. the generative, compare the samples from two distributions (e.g. WAE like AutoEncoder models, set-processing deep networks, etc) in their cost functions. Using all these methods one cannot train the model directly taking small size (in extreme -- one element) batches, due to the fact that samples are to be compared. We propose a generic approach to training such models using one-element mini-batches. The idea is based on splitting the batch in latent into parts: previous, i.e. historical, elements used for latent space distribution matching and the current ones, used both for latent distribution computation and the minimization process. Due to the smaller memory requirements, this allows to train networks on higher resolution images then in the classical approach.